This is the documentation section of the Kore Ledger project. In this place, you will find the description of the technology and its potential use cases, the background that led us to address its development, detailed technical information on the different components of the architecture, and different tutorials that will help you implement different traceability solutions.
This is the multi-page printable view of this section. Click here to print.
Documentation
- 1: Overview
- 1.1: DLT
- 1.2: Traceability
- 1.3: Value Proposal
- 1.4: Use Cases
- 1.5: Under the hood
- 2: Getting Started
- 2.1: Concepts
- 2.1.1: Governance
- 2.1.2: Subject
- 2.1.3: Roles
- 2.1.4: Schema
- 2.1.5: Events
- 2.1.6: Identity
- 2.1.7: Contracts
- 2.1.8: Node
- 2.2: Advanced concepts
- 2.2.1: Event approval process
- 2.2.2: Event evaluation process
- 2.2.3: Event validation process
- 2.3: Glossary
- 3: Learn
- 3.1: Governance
- 3.1.1: Governance structure
- 3.1.2: Governance scheme and contract
- 3.2: Contracts
- 3.2.1: Contracts in Kore
- 3.2.2: Programming contracts
- 3.3: Learn JSON Schema
- 3.4: Kore Base
- 3.4.1: Architecture
- 3.4.2: FFI
- 3.5: Kore Node
- 3.5.1: What is
- 3.5.2: Configuration
- 3.6: Kore Clients
- 3.6.1: Kore HTTP
- 3.6.2: Kore Modbus
- 3.7: Tools
- 4: Policies
- 4.1: Legal warning
- 4.2: Privacy
- 4.3: Equality and diversity
1 - Overview
Overview of Kore Ledger technology and its applications.
Kore Ledger is a Distributed Ledger Technology (DLT) designed and built specifically for traceability of assets and processes’ provenance and life cycle. It is complemented by a framework and governance model that facilitates interaction and cooperation between multiple actors in highly complex scenarios (circular economy, energy production, integral water cycle, agri-food production, etc.)
1.1 - DLT
Distributed Ledger Technology Concept.
What is a DLT?
DLT is an acronym for Distributed Ledger Technology. This concept refers to a distributed database, which is replicated and synchronized across multiple network nodes and accessible to various parties. This technology allows us to store identical record copies on different computers, making it easy for multiple participants to view and update it. Unlike traditional distributed databases, it works like a ledger: only new records can be added, and old ones cannot be deleted or modified. This idea has attracted attention in the last decade because one of its variants, blockchain technology, underpins most cryptocurrencies.
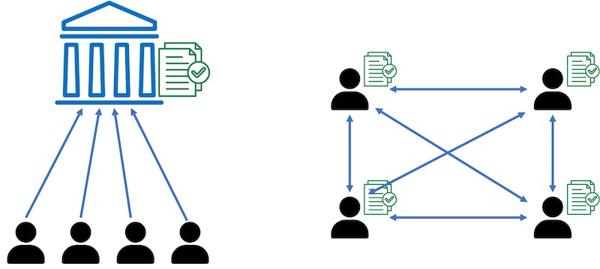
(Left) Centralized Ledger technology. (Right) Distributed Ledger technology.
Figure 1: Centralized ledger vs. Distributed ledger.
1.2 - Traceability
What is traceability and why is it so important?
The UNE 66.901-92 standard defines traceability as
“the ability to reconstruct the history of use or location of an item or product using a registered identification”
- Traceability allows products and goods to be tracked as they move along the value chain, obtaining reliable information on the origin of inputs, supplier sourcing practices and transformation processes.
- It offers companies the ability to identify strategic opportunities in optimizing value chains, innovate much faster, minimize the impact of internal and external supply interruptions, and offer certification of more sustainable processes and products.
- The digitalization of traceability is the starting point for new circular and transparent value chains that reduce the use of materials, and that reuse or recycle products, reducing costs and creating less waste.
1.3 - Value Proposal
The Kore Ledger Value Proposition.
Kore Ledger is the combination of the words “green” in the African language “hausa”, and “ledger”. It is a business initiative to provide the technology and framework necessary for the traceability of origin and life cycle of assets and processes.
The differentiating factor is that it will be done in a decentralized, secure and immune to manipulation manner, also guaranteeing the privacy of the data and the sustainability of the solutions. This approach provides a comprehensive, economical, easy-to-implement and non-invasive solution with the existing digitalization of our clients.
On the other hand, Kore Ledger technology offers the ability to link traceability information from different subjects and at different levels of their life cycle , which makes it the ideal solution in the field of circular economy, sustainable energy production, integral water cycle, carbon footprint, agri-food traceability, industrial safety, etc.
Kore Ledger offers the best technological infrastructure solution for the digitalization of asset and process traceability. Based on a secure distributed ledger technology that is immune to manipulation, it provides levels of scalability much higher than other equivalent solutions, and in a much more sustainable way.
- Providing a solutions production line that drastically reduces the time and cost of launching solutions to the market.
- Supported by a framework that facilitates the formalization of traceability models that satisfy the specific requirements of each client, offering an immediate return
With a technology designed for unlimited scalability, the ability to be executed on devices with limited resources (mobile, IoT,…), support for the most advanced cryptography and maximum energy efficiency.
What differentiates us from a blockchain?
| Appearance | Blockchain | Kore Ledger |
| Function |
|
|
| Cost |
|
|
| Efficiency |
|
|
1.4 - Use Cases
Different traceability use cases with Kore Ledger.
Kore has been designed with traceability use cases in mind. It is considered that in these use cases the vast majority of events are unilateral, which allows taking advantage of Kore’s differentiating features, such as ledger single ownership model. Some Kore technology use cases will be presented as examples to facilitate understanding.
Processes
Any process that requires traceability with high levels of security and confidence, is apt to be a suitable use case to be traced through Kore nodes, for instance, the water cycle. This process describes how the flow of water starts from a point A and passes through a series of other points until it finally returns to the point of origin, simulating a circular path. Along the way, the water flow passes through various entities and processes that cause its volume to decrease. Simultaneously, at some of these points it is possible to analyze the state of that flow by means of sensors or other systems that allow to obtain and generate additional information of the flow itself.
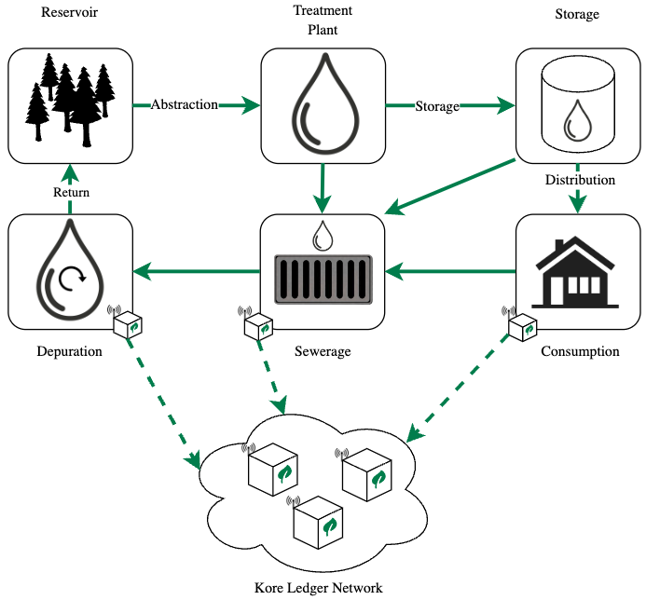
Figure 1: Water cycle with Kore Ledger.
Iot
IoT is defined as The Internet of things. The Internet of things describes physical objects (or groups of such objects) with sensors, processing ability, software and other technologies that connect and exchange data with other devices and systems over the Internet or other communications networks. For example, the smart city concept has recently been gaining momentum.
Today, the benefits of a city are not only limited to physical infrastructure, services and institutional support, but also to the availability and quality of communication channels, and the transmission and exploitation of knowledge from these channels to improve and efficiently provide resources to social infrastructures.
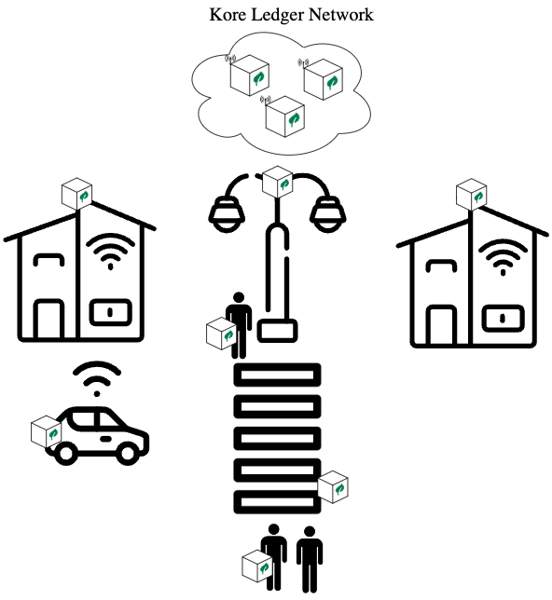
Figure 2: Smart City connected to Kore Ledger Network.
One of the most interesting processes within a smart city, both for its public health implications and its economic nature, is waste management. The first step is to collect the garbage provided by citizens in containers which have sensors or other systems that determine the weight of the container and how full they are. Once the sensor is activated at the value set by the company, the garbage truck picks up the container to take it to the recycling factory, where they are responsible for separating these elements and perform the relevant processes for recycling. Finally, when the process is finished, these materials are put back on sale so that they can be used again and the process explained above is repeated.
Beef Traceability
Beef is a common product in supermarkets and its traceability is crucial to guarantee its quality, safety and origin. With Kore, you can implement a traceability system for beef from field to table by following these steps:
- Livestock Breeding and Feeding: The system begins with the raising and feeding of livestock on farms. Kore can record information about where cattle come from, their genetics, diet, husbandry conditions and health. Data may include diet type (organic, conventional), medication use, and other important details.
- Slaughter and Processing: When cattle are slaughtered, Kore records process data, including quality controls, date and location of slaughter. During processing, meat cuts and by-products can be tracked, ensuring traceability of each piece.
- Transportation and Storage: Kore allows tracking of meat during transportation from the processing plant to distribution centers and stores. Transport conditions, such as temperature, can be monitored to ensure the meat remains in optimal condition.
- Distribution to Supermarkets: Once the meat reaches supermarkets, Kore can record data on its storage, rotation and display on shelves. Retailers can access detailed information about the origin of meat and its characteristics, allowing them to make informed sales decisions.
- Sale to the Final Consumer: Consumers can access traceability information through QR codes or labels on the meat packaging. This allows them to know the origin of the meat, its quality history and any other relevant information.
This level of traceability ensures that consumers receive high-quality beef and that food safety standards are met. Additionally, it helps prevent fraud and quickly identify problems in the event of foodborne illness outbreaks.
1.5 - Under the hood
Technologies used by Kore Ledger
Rust
Rust is a programming language initially developed by Graydon Hoare in 2006 while working at Mozilla, company that would later officially support the project in 2009, thus achieving its first stable version in 2014. Since then, the popularity and adoption of the language has been increasing due to its features, receiving support from significant companies in the industry such as Microsoft, Meta, Amazon and the Linux Foundation among others.
Rust is the main language of the Kore technology. Its main characteristic is the construction of secure code, it implements a series of features whose purpose is to guarantee memory safety, in addition to adding zero-cost abstractions that facilitate the use of the language without requiring complex syntaxes. Rust is able to provide these advantages without negatively affecting system performance, both from the point of view of the speed of a running process, as well as its energy consumption. In both characteristics, it maintains performances equal or similar to C and C++.
Rust was chosen as a technology precisely because of these characteristics. From Kore ledger, we attach great importance to the security of the developed software and its energy consumption and Rust was precisely the language that met our needs. Also, since it is a modern language, it includes certain utilities and/or features that would allow us to advance more quickly in the development of the technology.
LibP2P
Libp2p is a “stack of technologies” focused on the creation of peer-to-peer applications. Thus, LibP2P allows your application to build nodes capable of interpreting a number of selectable protocols, which can be both message transmission and encryption among others. Libp2p goes a step further by offering the necessary tools to build any protocol from scratch or even to create wrappers of other existing ones or simply to implement a new high-level layer for a protocol while maintaining its low-level operation. LibP2P also manages the transport layer of the node itself and offers solutions to problems known as “NAT Traversal”.
LibP2P also places special emphasis on modularity, in such a way that each and every one of the previously mentioned elements are isolated from each other, can be modified without affecting each other and can be combined as desired, maintaining the principle of single responsibility and allowing code reuse. Once a protocol is developed for LibP2P, it can be used in any application regardless of how different they are from each other. This level of modularity allows even different protocols to be used depending on the medium to be used.
LibP2P was chosen for Kore because of its innovative approach to the creation of P2P applications through its tools and utilities that greatly facilitate development. It was also influenced by the fact that it is a technology with a background in the Web3 sector, as it was originally part of IPFS and has been used in Polkadot and Substrate as well as Ethereum 2.0.
Tokio
Tokio is a library for Rust aimed at facilitating the creation of asynchronous and concurrent applications. It provides the necessary elements for the creation of an execution environment for task management, internally interpreted as “green threads” (which Rust does not natively support). As well, as channels for communication between them among. It is also quite easy to use thanks to its syntax focused on “async / await” and has high scalability thanks to the reduced cost of creating and deleting tasks.
Due to the previously mentioned characteristics and focusing on concurrency and scalability, Tokio is an adequate library for the needs you want to cover with Kore technology.
2 - Getting Started
What does a user need to know to benefit from the technology?
2.1 - Concepts
Definitions of key concepts in Kore Ledger.
2.1.1 - Governance
Governance Description.
The governance is the set of definitions and rules that establish how the different nodes participating in a network relate to the subjects of traceability and interact with each other. The components of governance are:
- The participating nodes.
- The schema of the attributes of the subjects.
- The contract to apply the events that modify the state of the subject.
- The permissions of each participant to participate in the network.
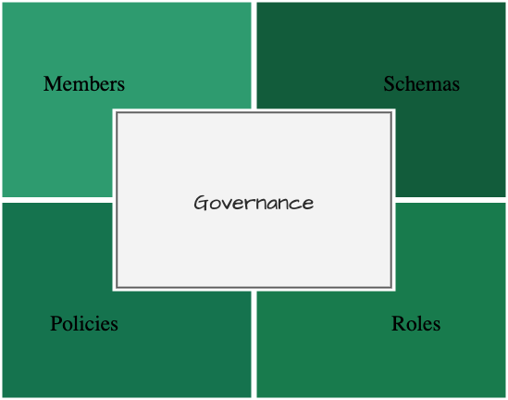
Figure 1: Governance components.
Members
These are the persons, entities or organizations that participate in governance and therefore may be part of the supported use cases. Each member declares a unique identifier representing the cryptographic material with which it will operate in the network, its identity .
Schemas
Schemas are the data structures that model the information stored in the subjects. Within a governance, different schemas can be defined to support different use cases. When a subject is created, it defines which governance it is associated with and which schema it will use. In addition, each schema has an associated contract that will allow you to modify the state of the subjects.
Roles
Roles represent groups of participants with some kind of common interest in a set of subjects. Roles allow us to assign permissions on these groups of subjects more easily than if we had to assign them individually to each member of the government.
Policies
The policies define the specific conditions under which the life cycle of an event is affected, such as the number of signatures required to carry out the evaluation, approval and validation processes. This is called quorum. The governance configuration allows the definition of [different types of quorum] , more or less restrictive, depending on the need of the use case.
CAUTION
As we know, the owner of a subject is the only one who can act on it , and therefore has absolute freedom to modify it. Governance cannot prevent malicious owners from trying to perform forbidden actions, but it does define the conditions under which the other participants ignore or penalize these malicious behaviors.Governance as a subject
The governance is a subject of traceability, since it can evolve and adapt to business needs, and therefore its lifecycle is also determined by a governance, which endows our infrastructure with transparency and trust for all participants.
Hierarchy of relationships
Governance defines the rules to be followed in a use case. However, the owner of a node is not limited to participate in a single use case. Combine this with the governance structure and you get the following hierarchy of relationships:
- One governance:
- define one or more: members, policies, schemas and roles.
- A governance: support one or more use cases.
- A participant (person, entity or organization):
- has an identity , and the identity acts as a member of a governance.
- runs a node that stores many subjects.
- Is involved in one or more use cases.
- A subject:
- depends on a governance.
- is modeled by a schema.
- has namespaces.
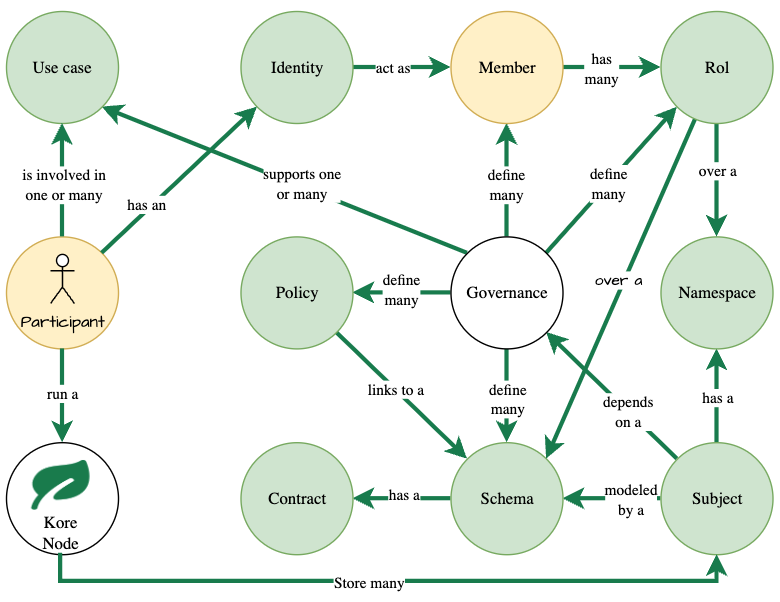
Figure 2: Hierarchy of relationships .
2.1.2 - Subject
Description of subject.
Instead of having a single ledger shared by all participants, the information is structured subject by subject. Subjects are logical entities that represent an asset or process within a network.
Each subject complies with the following:
- It contains a single microledger.
- It has a state modeled by a schema.
- It has a single owner.
- Depends on a governance.
Microledger
Each subject internally contains a ledger in which events affecting only that subject are recorded, the microledger. This microledger is a set of events chained together using cryptographic mechanisms. It is similar to a blockchain in that the different elements of the chain are related including the cryptographic fingerprint of the immediately preceding element, but, unlike blockchains where each block may include a set of transactions, possibly from different accounts, in the microledger. each element represents a single event of the subject itself.
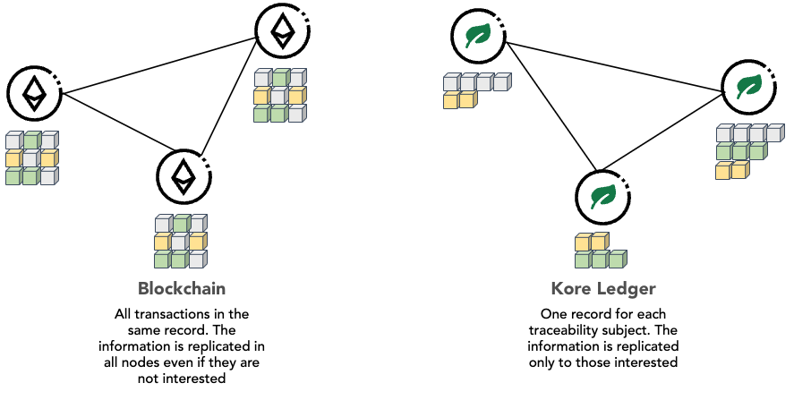
Figure 1: Event registration in Blockchain and Kore Ledger.
Subject State
The state is the representation of the information stored by a subject at a given instant, usually the current time. The state is obtained by applying, one after the other, the different events of the microledger on the initial state of the subject defined in its event-genesis.

INFO
The state structure must correspond to a valid schema. For more information about schemas, please visit the Schemas.CAUTION
Unlike other DLTs, Kore has no data tables. The information is stored in a single entity, the subject state. This entity should represent only the final state of our subject, while the details of the different events will be stored in the microledger.Ownership model
Any subject has a single owner, this being the only participant in the network that can make effective modifications on the subject, i.e., add events in the microledger. However, other participants, the senders, can generate event requests. These event requests are signed by the sender and sent to the subject owner.
Belonging to a governance
A subject always exists within a use case. Governance is the definition of the rules by which the use case is governed. What types of subjects can be created or who can create them are some of the rules that are defined in governance. Although a subject can only belong to one governance, a node can manage subjects of different governance, so that the same node can participate simultaneously in different use cases.
Namespace
When a subject is created, certain information is associated with it, such as governance, schema and a namespace. The namespace is associated with the use case and governance, as it is the mechanism by which stakeholders can be segmented. In the same use case, not all participants may be interested in all subjects, but only in a subset of them.
Subject identifier and keys
Each subject, at the time of its creation, is assigned a pair of cryptographic keys with which to sign the events of its microledger. From the public key and other metadata, its Subject Identifier (subjectId) , which uniquely represents it in the network, is generated.
2.1.3 - Roles
Role description.
Each participant in the network interacts with it based on different interests. These interests are represented in Kore as roles
Owner
Owns the traceability subject and is the node responsible for recording events. They have full control over the subject because they own the cryptographic material with permissions to modify it.
INFO
The ownership of the subject can be obtained by creating it or receiving it from the previous owner.Issuer
Application authorized to issue event requests, even if it is not a network node. All it needs to participate in the network is a cryptographic key pair that allows signing events, as well as having the necessary permissions in governance.
Evaluator
Evaluators assume a crucial role within the governance framework, being responsible for carrying out the evaluation process. This process performs the execution of a contract, which generally results in a change in the subject’s status.
Approver
In order for certain event requests to obtain approval and be added to a subject’s microledger, a number of signatures are required. The acquisition of these signatures depends on the outcome of the evaluation. During the evaluation of a contract, a decision is made on the need for approval, which may be influenced by the roles of the requesting issuer.
Validator
Node that validates the order of events to guarantee immunity to manipulation. This is achieved by not signing events with the same subject ID and sequence number.
Witness
Nodes interested in keeping a copy of the log, also providing resilience.
2.1.4 - Schema
Description of schema.
The schema is the structure of the state contained in a subject.
The schemas are defined within a governance and are therefore distributed together with it. Different governances may define equivalent schemas, however, for all intents and purposes, since they belong to different governances, they are considered different schemas.
The schemas are composed of 2 elements:
- A unique identifier. Each schema has an identifier that allows it to be referenced within the governance in which it is defined. Different schemas can be defined within the same governance. In addition, as long as they have different identifiers, you can create schemas with the same content.
- A content. It is the data structure used to validate the status of the subjects.
{
"id": {"type":"string"},
"content": {"type": "object"}
}
INFO
If you want to learn how to define a JSON schema, visit the following link.2.1.5 - Events
Events within the Kore Ledger network.
Events are the data structures that represent the facts to be tracked during the life of a subject. These structures constitute the micrologger, i.e. the chain of events.
Each event is composed of the following:
- The request that generated the event.
- The cryptographic fingerprint of the previous event to form the chain.
- A set of meta-information related to the topic and the event.
- A set of different signatures that are added as the event progresses through its lifecycle.
Life cycle
The governance determines the process by which events are incorporated into the life cycle of the traceability subject. The event lifecycle is composed of 6 stages, from its request for generation to its distribution.
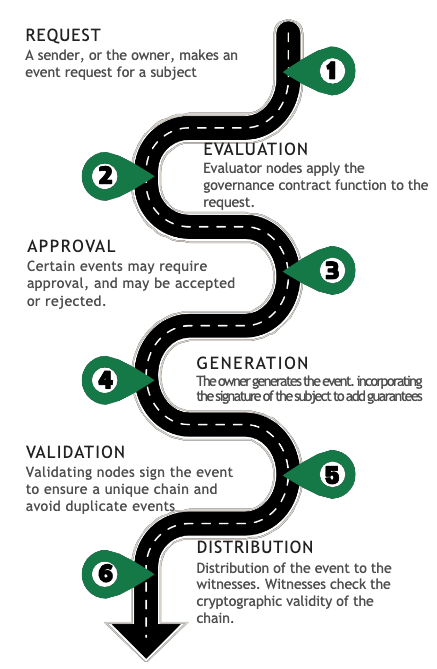
Figure 1: Life cycle.
1. Request
To change the state of a subject it is necessary to add an event to its micro-ledger. To do this, the first step is to generate an event request . In Kore only the owner of the subject can generate events on the subject. However, these events can be generated by requests from other participants, known as issuers . In this way, the owner acts as the organizer of event requests, which can be generated by himself or by other participants.
CAUTION
As the only one who can enter events in the micro-logger, the owner has the final say on whether or not to create an event from a request, even if it is sent by another participant. In situations where it is necessary to ensure that the request has been logged, additional security measures to those offered by Kore must be implemented.Event requests contain the following:
- The type of event to generate.
- The information to be included in the microledger, e.g., to modify the subject status.
- The signature of the sender, which may be the owner of the subject or another participant with sufficient permissions.
2. Evaluation
In Kore there are different types of events and not all of them share the same life cycle. In the case of fact events there are 2 additional steps: evaluation and approval.
The evaluation phase corresponds to the execution of the contract. For this, the subject holder sends the following information to the evaluators:
- the current status of the subject, since the evaluators do not need to witness it, and therefore may not know its status;
- the subject’s metadata, such as its schema and namespace.
After receiving the information, the evaluator executes the contract and returns the modified subject state to the subject owner, the need or not for approval and his signature. The owner must collect as many evaluator signatures as governance dictates.
3. Approval
The evaluation of some contracts may determine that the result, even if properly executed, requires approval. This means that, in order to be accepted by the other participants, it is necessary to include a number of additional signatures from other participants, the approvers. These approvers sign for or against an event request. The rules defined in the governance indicate which signatures are necessary for an event request to be approved and, therefore, for an event to be generated from this request.
The decision to approve or disapprove a request may depend on the participation of an individual or it may depend on some IT system, such as a business intelligence process.
4. Generation
The next step is the actual generation of the event. The event is composed including the request, the contract evaluation, the signatures of the evaluators and approvers, the hash of the previous event and a series of metadata associated with the event. The event is then signed with the subject cryptographic material, which ensures that only the owner of the subject was able to generate the event.
5. Validation
A generated event cannot be distributed directly. The reason is that the other participants in the network have no guarantee that the owner has not generated different versions of the event and distributed them according to his own interests. To avoid this, the validation phase arises. Several network participants, the validators, provide their signature to the event, guaranteeing that a single event exists. Not all subjects require the signatures of the same validators. Governance defines which participants must provide their signatures and how many signatures are required. The number of signatures will depend on the use case and the network’s trust in the members acting as validators.
6. Distribution
Once there are enough validation signatures, the event is complete and can be distributed to the rest of the network participants. The owner sends the event along with the validation signatures to the tokens. The witnesses, once the validity of the set has been verified, will incorporate the event into the microledger, and will delete the validation signatures they had stored for the previous event.
Types of events
| Event | Description |
|---|---|
| Start | Initializes the event log of a subject, establishing the participants and the governance of the ledger. |
| State | State records change the subject’s properties, so its state is modified. |
| Fact | Events related to the subject’s function or environment but which do not change its properties. |
| Transfer | Transfers ownership of the subject to a new owner. A key rotation occurs to prevent manipulation of previous events by the new owner. |
| EOL | End-of-life event that terminates event registration, preventing new additions. |
As for the structure and contents of the events, we have relied on industry-recognized design solutions 1. The usual approach is to structure the event in a header, with a common structure for all events, including their metadata, and a payload with specific information for each event.
Example
Diagram generated an event type Fact.
sequenceDiagram
actor Issuer
actor Owner
actor Evaluators
actor Approvers
actor Validators
actor Witnesses
Note over Owner: Request phase
Issuer->>Owner: Event request
Note over Owner: Evaluation phase
alt Is a Fact Event
Owner->>Evaluators: Evaluation request
Evaluators->>Owner: Evaluation respond
end
Note over Owner: Approval phase
alt Contract evaluation says that approval is required
Owner->>Approvers: Approval request
Approvers->>Owner: Approval respond
end
Note over Owner: Composition phase
Owner->>Owner: Event generation
Note over Owner: Validation phase
Owner->>Owner: Validation proof generation
Owner->>Validators: Validation request
Validators->>Owner: Validation response
Note over Owner: Distribution phase
Owner->>Witnesses: Event
Witnesses->>Owner: ACK
Referencias
-
Event Processing in Action - Opher Etzion y Peter Niblett (2010). Manning Publications Co., 3 Lewis Street Greenwich, Estados Unidos. ISBN: 978-1-935182-21-4. ↩︎
2.1.6 - Identity
Identity disciption in Kore Ledger.
Each participant in a Kore Ledger network has a unique identifier and a private key that allows him/her to sign the transactions made. In addition, depending on their interest in each subject and their level of involvement with the network, each participant will have one or more different roles.
Given the strong influence of KERI1 in our project, the reflection on the reference model to establish the identifiers in our protocol starts from Zooko’s triangle2. This is a trilemma that defines three desirable properties desirable in the identifiers of a network protocol, of which only two can be simultaneously. These properties are:
- Human Meaningful: Meaningful and memorable (low entropy) names to users.
- Secure: The amount of damage a malicious entity can inflict on the system should be as low as possible.
- Decentralized: Names are correctly resolved to their respective entities without using a central authority or service.
Although several solutions to the trilemma have already been proposed, we have prioritized decentralization and security to shortly implement a design equivalent to the Ethereum Name Service . Specifically, in our approach we have considered three types of identifiers, which in turn represent three types of cryptographic material:
- Public key, the identifier of the roles participating in the network.
- Message digest, the identifier of the content of messages resulting from applying a hash function to this content.
- Cryptographic signature, the identifier of the signatures made by the roles on the messages, which serves as verifiable proof.
This cryptographic material is large binary numbers, which presents a challenge when used as identifiers. The best way to handle identifiers is through a string of characters and, for conversion, we have adopted the Base64 encoding, which encodes every 3 bytes of a binary number into 4 ASCII characters. As the cryptographic material to be managed is not a multiple of 3 (32 bytes and 64 bytes), it is filled with an additional character (32 bytes) or two (64 bytes). As in KERI, we have taken advantage of these additional characters to establish a derivation code to determine the type of material by placing the derivation character(s) at the beginning.
The following table details the currently supported derivation codes:
| Code | Type of Identifier |
|---|---|
| E | Public Key Ed25519 |
| S | Public Key Secp256k1 |
| J | Digest Blake3 (256 bits) |
| OJ | |
| L | Digest SHA2 (256 bits) |
| OL | Digest SHA2 (512 bits) |
| M | Digest SHA3 (256 bits) |
| OM | Digest SHA3 (512 bits) |
New types of cryptographic material have already been incorporated into the roadmap, thinking of devices limited to operations with RSA3 or P2564, and post-quantum cryptography, such as Crystal-Dilithium5. In the case of RSA or Crystal-Dilithium, we are dealing with a binary size of cryptographic material that is too large to be represented as identifiers, so we will have to incorporate a different derivation mechanism.
References
-
KERI White Paper - Samuel L. Smith (2021) “Key Event Receipt Infrastructure (KERI).” ↩︎
-
Zooko’s Triangle - Wikipedia (2022). ↩︎
-
RSA - Rivest, Shamir y Adleman (1978) “A Method for Obtaining Digital Signatures and Public-Key Cryptosystems.” ↩︎
-
NIST - Mehmet Adalier y Antara Teknik (2015) “Efficient and Secure Elliptic Curve Cryptography Implementation of Curve P-256.” ↩︎
-
CRYSTALS-Dilithium - Léo Ducas et al. (2021) “CRYSTALS-Dilithium – Algorithm Specifications and Supporting Documentation (Version 3.1).” ↩︎
2.1.7 - Contracts
Kore Ledger Contracts.
Definition
A contract in Kore Ledger is the rules, agreements and actions derived from those agreements that are executed on each event request in the life cycle of a subject. Just as a subject always has an associated schema, which defines the set of properties of its state, such a schema always has an associated contract. Changes in its life cycle occur exclusively through the execution of this contract.
Structure
Future work
In its definition, we limit ourselves exclusively to the term “contract”, as opposed to the denomination used in blockchain technologies of “smart contract”, in order to provide greater precision on its intentionality. So-called “smart contracts” are not smart contracts and are just programs that are executed under certain pre-set conditions. In our case, the goal is to offer a contract structure based on a formal language fundamentally inspired by the proposed FCL (Formal Contract Language) 1.
References
2.1.8 - Node
Type of Node
Bootstrap
These are the nodes with which to establish a connection to the traceability network if an access license is available. They also provide secure circuits to communicate with the ephemeral nodes.
Addressable
Nodes that require a public address. Governance can be created on them so that the ephemeral emits the corresponding events.
Ephemeral
These (which will normally be behind a NAT/Firewall) will be in charge of emitting events to the Bootstrap nodes.
2.2 - Advanced concepts
Description of Advanced concepts.
2.2.1 - Event approval process
Description of Event approval process.
The approval phase involves asking the approvers to vote for or against the application of an event. This process can be automated but tends to be manual. The response requires interaction with the Kore API if it’s set to manual, so it requires a user who can interact with it and therefore generally takes longer than the other phases.
The approvers are defined by the governance, so they must possess it in order to carry out the evaluation, otherwise they would not have access to the contract, which in turn is stored in the state of the governance.
The approvers will only carry out the evaluation if the version of the governance that the subject’s owner has coincides with that of the approver. If it is lower or higher, an appropriate message for each case is sent to the subject’s owner.
The approval process consists of the following steps:
- The subject owner checks whether the event request requires approval by looking at the response of the evaluators.
- If the request requires it, an approval request is sent to the different approvers.
- Once each approver has the request, they will be able to vote, both for and against, and will send it back to the owner of the subject.
- Every time the owner receives a vote, he will check the following:
- There are enough positive votes for the application to be accepted.
- There are so many negative votes that it is impossible to get the application approved. In both cases, the owner will generate an event. In the case that the vote has not been successful, the event will be generated but it will not produce changes in the state of the subject, remaining merely for informational purposes.
CAUTION
It is important to remember that the subject owner is the only one who can force an effective change on a subject. Therefore, the owner, after the approval process, could decide whether or not to include the event in the chain. This would not follow the standard behavior defined by Kore, but it would not break compatibility.sequenceDiagram
%% Comentarios pendientes a que este la invocación externa
%% actor Invocador
actor Owner
actor Evaluator
actor Approver 1
actor Approver 2
actor Approver 3
%% Invocador->>Owner: Submit an event request
Note over Evaluator: Evaluation phase
alt Need for approval detected
Owner->Approver 3: Transmit approval request to all approvers
Approver 1-->>Owner: Receive
Approver 2-->>Owner: Receive
Approver 3-->>Owner: Not receive
Note over Owner: Wait
Approver 1->>Owner: Vote yes
Approver 2->>Owner: vote no
Note over Owner: Receive vote request
Owner->>Approver 3: Transmit request
Approver 3-->>Owner: Receive
Note over Owner: Wait
Approver 3->>Owner: Vote yes
Note over Owner: Receive vote request
end
alt Positive quorum
Owner->>Owner: Generate event and update subject
else Negative quorum
Owner->>Owner: Generate event
end
Owner->Approver 3: Event goes to the validation phase
2.2.2 - Event evaluation process
Description of Event evaluation process.
The evaluation phase consists of the owner of th subject sending an evaluation request to the evaluators, just after the issuer generated an event request with the event type and its content. Currently, evaluation is only present in Fact type events, in the other types it’s skipped. These events affect a certain subject to establish a fact that may or may not modify the subject’s state. A context is also sent containing the necessary information for the evaluators to execute the contract that contains the evaluation logic for our subject, such as previous state, whether the issuer is the owner of the subject, etc. This is the case because the evaluators do not necessarily have a copy of the subject, so they need this data, which includes everything necessary for the execution of the contract.
The evaluators are defined by the governance, so they must possess it in order to carry out the evaluation, otherwise they would not have access to the contract, which in turn is stored in the state of the governance.
The result of applying the event to the subject in terms of property modification is carried out by the evaluators. They have the ability to compile and execute contracts compiled in web assembly.
The Fact event request contains the necessary information to execute one of the functions of the contract (or not, in which case a failed evaluation occurs and the subject owner is notified). The response includes whether the evaluation was successful or failed, if it is necessary to go through the approval phase and the JSON patch that, when applied to the subject’s state, will produce the state change, as well as the hash of the updated state.
The evaluators response is signed by them so that the witnesses can verify that quorum has been reached in the evaluation phase and that the correct evaluators have signed.
The evaluators will only carry out the evaluation if the version of the governance that the subject’s owner has coincides with that of the evaluator. If it is lower or higher, an appropriate message for each case is sent to the subject’s owner.
For issuers, when the governance to which the subject is assigned is updated, the process must be restarted from the beginning of the evaluation, whether you were still in the evaluation phase or already in the approval phase. This is because events must be evaluated/approved with the latest version of governance available.
sequenceDiagram
actor Owner as Owner
actor Evaluator1 as Evaluator 1
actor Evaluator2 as Evaluator 2
actor Evaluator3 as Evaluator 3
Owner->>Evaluator1: Generate Evaluation Request
Owner->>Evaluator2: Generate Evaluation Request
Owner->>Evaluator3: Generate Evaluation Request
alt Governance Access Granted and Governance Version Matches
Evaluator1->>Evaluator1: Check Governance and Execute Contract
Evaluator2->>Evaluator2: Check Governance and Execute Contract
Evaluator3->>Evaluator3: Check Governance and Execute Contract
alt Evaluation Successful
Evaluator1->>Owner: Return Evaluation Response and Evaluator's Signature
Evaluator2->>Owner: Return Evaluation Response and Evaluator's Signature
Evaluator3->>Owner: Return Evaluation Response and Evaluator's Signature
else Evaluation Failed
Evaluator1->>Owner: Return Evaluation Response (with failed status) and Evaluator's Signature
Evaluator2->>Owner: Return Evaluation Response (with failed status) and Evaluator's Signature
Evaluator3->>Owner: Return Evaluation Response (with failed status) and Evaluator's Signature
end
else Governance Access Denied or Governance Version Mismatch
Evaluator1->>Owner: Send Appropriate Message
Evaluator2->>Owner: Send Appropriate Message
Evaluator3->>Owner: Send Appropriate Message
Owner->>Owner: Restart Evaluation Process
end
2.2.3 - Event validation process
Description of Event validation process.
The validation process is the last step before achieving a valid event that can be joined to the subject’s chain. The aim of this phase is to ensure the uniqueness of the subject’s chain. It is based on the collection of signatures from the validators, which are defined in the governance. It does not produce a change in the event itself, as the signatures are not included in the event, but they are necessary to validate it in the eyes of the witnesses. It is noteworthy that for the uniqueness of the chain to be fully effective, the validation quorum needs to consist of the majority of validators. This is because if not, several chains could be validated with different validators for each one if the sum of the signature percentage for all quorums does not exceed 100%.
Proof of validation
What the validators sign is called proof of validation, the event itself is not directly signed. This is done to ensure the privacy of the event’s data and at the same time add additional information that allows the validation process to be safer. In turn, when the owners of the subjects send the proof to the validators, it is also signed with the subject’s cryptographic material. It has this form:
pub struct ValidationProof {
/// The identifier of the subject being validated.
pub subject_id: DigestIdentifier,
/// The identifier of the schema used to validate the subject.
pub schema_id: String,
/// The namespace of the subject being validated.
pub namespace: String,
/// The name of the subject being validated.
pub name: String,
/// The identifier of the public key of the subject being validated.
pub subject_public_key: KeyIdentifier,
/// The identifier of the governance contract associated with the subject being validated.
pub governance_id: DigestIdentifier,
/// The version of the governance contract that created the subject being validated.
pub genesis_governance_version: u64,
/// The sequence number of the subject being validated.
pub sn: u64,
/// The identifier of the previous event in the validation chain.
pub prev_event_hash: DigestIdentifier,
/// The identifier of the current event in the validation chain.
pub event_hash: DigestIdentifier,
/// The version of the governance contract used to validate the subject.
pub governance_version: u64,
}
Data such as the governance_version, which is used to verify that the vote should only be returned if it matches the subject’s governance version for the validator, and the subject_public_key is the one used to validate the owner’s signature of the next proof of validation that reaches the validator.
If the validator has the previous proof, they can validate certain aspects, such as the prev_event_hash of the new one matches the event_hash of the previous one. The validators’ database will always store the last proof they signed for each subject. This allows them never to sign two proofs for the same subject_id and sn but with different other data (except for the governance_version). This guarantees the uniqueness of the chain. The ability to change the governance_version is due to what we discussed earlier: if a validator receives a proof with a different governance version than theirs, they should not sign it. Therefore, facing updates of the governance in the middle of a validation process, the owner must restart said process, adapting the governance_version of the proof to the new one.
Another interesting point is the case where validators do not have the previous proof to validate the new one. There is no scenario where validators always have the previous proof, since even when the quorum requires 100% of the signatures, if a change in governance adds a new validator, they will not have the previous proof. This is why when a validation is requested, it should send:
pub struct ValidationEvent {
pub proof: ValidationProof,
pub subject_signature: Signature,
pub previous_proof: Option<ValidationProof>,
pub prev_event_validation_signatures: HashSet<Signature>,
}
The previous proof is optional because it does not exist in the case of event 0. The hashset of signatures includes all the signatures of the validators that allow the previous proof to have reached quorum. With this data, the validator can trust the previous proof sent to them if they do not previously have it.
The communication to request validation and to send validation is direct between the owner and the validator and is carried out asynchronously.
Correct Chain
As we mentioned earlier, the validation phase focuses on achieving a unique chain, but not on whether this chain is correct. This responsibility ultimately falls on the witnesses, who are the subject’s stakeholders. The validators do not need to have the subject’s updated chain to validate the next proof, as the proofs are self-contained and at most require information from the previous proof. But nothing prevents a malicious owner from sending erroneous data in the proof, the validators will not realize it because they do not have the necessary context and will sign as if everything was correct. The witnesses, however, do have the updated subject, so they can detect this kind of tricks. If something like this were to happen, the witnesses are the ones responsible for reporting it and the subject would be blocked.
Sequence Diagram
sequenceDiagram
actor Owner as Owner
actor Validator1 as Validator 1
actor Validator2 as Validator 2
actor Validator3 as Validator 3
actor Witness as Witness
Owner->>Validator1: Send ValidationEvent
Owner->>Validator2: Send ValidationEvent
Owner->>Validator3: Send ValidationEvent
alt Governance Version Matches and Proofs are Valid
Validator1->>Validator1: Inspect Governance, Check Last Proof and Signatures
Validator2->>Validator2: Inspect Governance, Check Last Proof and Signatures
Validator3->>Validator3: Inspect Governance, Check Last Proof and Signatures
Validator1->>Owner: Return ValidationEventResponse with Validator's Signature
Validator2->>Owner: Return ValidationEventResponse with Validator's Signature
Validator3->>Owner: Return ValidationEventResponse with Validator's Signature
else Governance Version Mismatch or Proofs are Invalid
Validator1->>Owner: Send Appropriate Message (if applicable)
Validator2->>Owner: Send Appropriate Message (if applicable)
Validator3->>Owner: Send Appropriate Message (if applicable)
Note over Validator1,Validator3: End Process (No Response)
end
Owner->>Owner: Collect Enough Validator Signatures
Owner->>Witness: Create Event in Ledger and Distribute
2.3 - Glossary
Definition of concepts
A
Approver
Some event requests require a series of signatures to be approved and become part of a subject’s microledger. This signature collection is a voting process where participants can vote in favor or against. These participants, defined in governance, are the approvers.
B
Bootstrap
It is part of the Kademlia protocol. It is the name of the node that is used for all news nodes that want to join the P2P Network to be discovered by all others.
Blockchain
Blockchain is a subtype of DLT, and therefore we can say that it is fundamentally a distributed, decentralized, shared, and immutable database.
C
Cryptography
It is the practice and study of techniques for secure communication in the presence of adversarial behavior.
D
DLT
- Immutable and tamper-resistant. It implements cryptographic security mechanisms that prevent its content from being altered, or at least, if any node tries to modify the information, it can be easily detected and blocked. Stands for “Distributed Ledger Technology”. A DLT is nothing more than a database that acts as such a ledger but also has, to a greater or lesser extent, the following characteristics:
- It is distributed and decentralised.
- Shared.
- Immutable and tamper-resistant.
E
Edge Devices
A device that provides an entry point into enterprise or service provider kore networks.
Event
The incident that occurs when the state of a subject is intended to be modified.
F
Fog Computing
It is an architecture that uses edge devices to carry out a substantial amount of computation, storage and communication locally and routed over the internet backbone.
Fog GateWay
Synonym for Edge Devices. A device that provides an entry point into enterprise or service provider kore networks.
G
Governance
Governance is a structure through which a participant or user of a system agrees to use the system. We can easily say that there are three principles that dictate governance. These principles include:
- Governing
- Rules
- Participants
K
Kademlia
It is a DTL that defines the structure of the network and how the information is exchanged through node lookups. The communications it’s done using UDP and in the process, an overlay network of nodes identified by an ID is created. This ID is not only to useful to identify the node but also useful to determine the distance between two nodes so the protocol can determine with whom it should communicate.
Kore
Stands for “Tracking (Autonomous) of Provenance and Lifecycle Events”. Kore is a permissioned DLT solution for traceability of assets and processes.
Kore Node
Official client to create a Kore Node. It is the easiest way to work with Kore as it is a simple console application that provides everything needed to build a node (Kore Base, API Rest and different mechanisms settings).
Kore Base
It is the library that implements most of the Kore functionality (creation and management of subjects and their associated microledgers, implementation of the P2P protocol for communication between nodes and database persistence). Any application that wants to be part of a Kore network must make use of this library from the API it exposes.
Kore Network
It is the P2P network created by all the Kore nodes in operation.
L
Ledger
A ledger is an accounting concept that basically defines a ledger in which information is always being added, usually in the form of transactions.
M
Microledger
The microledger is a set of events chained together using cryptographic mechanisms.
Multiaddr
A multiaddress (often abbreviated multiaddr), is a convention for encoding multiple layers of addressing information into a single “future-proof” path structure. It human-readable and machine-optimized encodings of common transport and overlay protocols and allows many layers of addressing to be combined and used together.
N
Node
It is a computer connected to other computers that follows rules and shares information.
P
P2P
It is a distributed application architecture that partitions tasks or workloads between peers equally privileged and equipotent participants in the network that make up.
S
Subject
Subjects are a logical entity or process that stores all the data necessary to define itself and that emits events throughout its life cycle with an order of emission determined by itself.
T
Transaction
It is an agreement or communication between 2 different entities to accept a change in the state of a subject.
V
Validator
The validator is a network participant who provides the security signature to the subject. The validator maintains a complete copy of the subjects it validates and commits to the network not to accept more than one version of the same event.
W
Witness
Participant interested in having a copy of the subject and the information it stores.
3 - Learn
Learn Kore Ledger technology.
3.1 - Governance
Governance documentation.
3.1.1 - Governance structure
Structure that makes up governance.
In this page we will describe the governance structure and configuration. If you want to know more about what governance visit the Governance page.
GOVERNANCE EXAMPLE
Click to look a full governance example. Each section will be discussed separately in the following sections.
{
"members": [
{
"name": "Company1",
"id": "ED8MpwKh3OjPEw_hQdqJixrXlKzpVzdvHf2DqrPvdz7Y"
},
{
"name": "Company2",
"id": "EXjEOmKsvlXvQdEz1Z6uuDO_zJJ8LNDuPi6qPGuAwePU"
}
],
"schemas": [
{
"id": "Test",
"schema": {
"type": "object",
"additionalProperties": false,
"required": ["temperature", "location"],
"properties": {
"temperatura": {
"type": "integer"
},
"localizacion": {
"type": "string"
}
}
},
"initial_value": {
"temperatura": 0,
"localizacion": ""
},
"contract": {
"raw": "dXNlIHNlcmRlOjp7U2VyaWFsaXplLCBEZXNlcmlhbGl6ZX07Cgptb2Qgc2RrOwoKI1tkZXJpdmUoU2VyaWFsaXplLCBEZXNlcmlhbGl6ZSwgQ2xvbmUpXQpzdHJ1Y3QgU3RhdGUgewogIHB1YiBvbmU6IHUzMiwKICBwdWIgdHdvOiB1MzIsCiAgcHViIHRocmVlOiB1MzIKfQoKI1tkZXJpdmUoU2VyaWFsaXplLCBEZXNlcmlhbGl6ZSldCmVudW0gU3RhdGVFdmVudCB7CiAgTW9kT25lIHsgZGF0YTogdTMyIH0sCiAgTW9kVHdvIHsgZGF0YTogdTMyIH0sCiAgTW9kVGhyZWUgeyBkYXRhOiB1MzIgfSwKICBNb2RBbGwgeyBvbmU6IHUzMiwgdHdvOiB1MzIsIHRocmVlOiB1MzIgfQp9CgojW25vX21hbmdsZV0KcHViIHVuc2FmZSBmbiBtYWluX2Z1bmN0aW9uKHN0YXRlX3B0cjogaTMyLCBldmVudF9wdHI6IGkzMiwgaXNfb3duZXI6IGkzMikgLT4gdTMyIHsKICAgIHNkazo6ZXhlY3V0ZV9jb250cmFjdChzdGF0ZV9wdHIsIGV2ZW50X3B0ciwgaXNfb3duZXIsIGNvbnRyYWN0X2xvZ2ljKQp9CgpmbiBjb250cmFjdF9sb2dpYygKICBjb250ZXh0OiAmc2RrOjpDb250ZXh0PFN0YXRlLCBTdGF0ZUV2ZW50PiwKICBjb250cmFjdF9yZXN1bHQ6ICZtdXQgc2RrOjpDb250cmFjdFJlc3VsdDxTdGF0ZT4sCikgewogIGxldCBzdGF0ZSA9ICZtdXQgY29udHJhY3RfcmVzdWx0LmZpbmFsX3N0YXRlOwogIG1hdGNoIGNvbnRleHQuZXZlbnQgewogICAgICBTdGF0ZUV2ZW50OjpNb2RPbmUgeyBkYXRhIH0gPT4gewogICAgICAgIHN0YXRlLm9uZSA9IGRhdGE7CiAgICAgIH0sCiAgICAgIFN0YXRlRXZlbnQ6Ok1vZFR3byB7IGRhdGEgfSA9PiB7CiAgICAgICAgc3RhdGUudHdvID0gZGF0YTsKICAgICAgfSwKICAgICAgU3RhdGVFdmVudDo6TW9kVGhyZWUgeyBkYXRhIH0gPT4gewogICAgICAgIHN0YXRlLnRocmVlID0gZGF0YTsKICAgICAgfSwKICAgICAgU3RhdGVFdmVudDo6TW9kQWxsIHsgb25lLCB0d28sIHRocmVlIH0gPT4gewogICAgICAgIHN0YXRlLm9uZSA9IG9uZTsKICAgICAgICBzdGF0ZS50d28gPSB0d287CiAgICAgICAgc3RhdGUudGhyZWUgPSB0aHJlZTsKICAgICAgfQogIH0KICBjb250cmFjdF9yZXN1bHQuc3VjY2VzcyA9IHRydWU7Cn0="
}
}
],
"policies": [
{
"id": "Test",
"validate": {
"quorum": {
"PROCENTAJE": 0.5
}
},
"evaluate": {
"quorum": "MAJORITY"
},
"approve": {
"quorum": {
"FIXED": 1
}
}
},
{
"id": "governance",
"validate": {
"quorum": {
"PROCENTAJE": 0.5
}
},
"evaluate": {
"quorum": "MAJORITY"
},
"approve": {
"quorum": {
"FIXED": 1
}
}
}
],
"roles": [
{
"who": "MEMBERS",
"namespace": "",
"role": "CREATOR",
"schema": {
"ID": "Test"
}
},
{
"who": "MEMBERS",
"namespace": "",
"role": "WITNESS",
"schema": {
"ID": "Test"
}
},
{
"who": "MEMBERS",
"namespace": "",
"role": "EVALUATOR",
"schema": "ALL"
},
{
"who": {
"NAME": "Company1"
},
"namespace": "",
"role": "APPROVER",
"schema": "ALL"
}
]
}
Members
This property allows us to define the conditions that must be met in the different phases of generating an event that requires the participation of different members, such as approval, evaluation, and validation.
- name: A short, colloquial name by which the node is known in the network. It serves no functionality other than being descriptive. It does not act as a unique identifier within the governance.
- id: Corresponds to the controller-id of the node. Acts as a unique identifier within the network and corresponds to the node’s cryptographic public key.
Schemas
Defines the list of schemas that are allowed to be used in the subjects associated with governance. Each scheme includes the following properties:
- id: Schema unique identifier.
- schema: Schema description in JSON-Schema format.
- initial_value: JSON Object that represents the initial state of a newly created subject for this schema.
- contract: The compiled contract in Raw String base 64.
Roles
In this section, we define who are in charge of giving their consent for the event to progress through the different phases of its life cycle (evaluation, approval, and validation), and on the other hand, it also serves to indicate who can perform certain actions (creation of subjects and external invocation).
- who: Indicates who the Role affects, it can be a specific id (public key), a member of the governance identified by their name, all members, both members and outsiders, or only outsiders.
- ID{ID}: Public Key of the member.
- NAME{NAME}: Name of the member.
- MEMBERS: All members.
- ALL: All members and externs.
- NOT_MEMBERS: All externs.
- namespace: It makes the role in question only valid if it matches the namespace of the subject for which the list of signatories or permissions is being obtained. If it is not present or it’s empty, it’s assumed to apply universally, as if it were the wildcard
*. For the time being, we are not supporting complex wildcards, but implicitly, if we set a namespace, it encompasses everything below it. For instance:- open is equivalent to
open*, but not toopen - open.dev is equivalent to
open.dev*, but not toopen.dev - If it’s empty, it equates to everything, that is,
*.
- open is equivalent to
- role: Indicates what phase it affects:
- VALIDATOR: For the validation phase.
- CREATOR: Indicates who can create subjects of this type.
- ISSUER: Indicates who can invoke the external invocation of this type.
- WITNESS: Indicates who are the witness of the subject.
- APPROVER: Indicates who are the approvators of the subject. Required for the approval phase.
- EVALUATOR: Indicates who are the evaluators of the subject. Required for the evaluation phase.
- schema: Indicates which schemas are affected by the Role. They can be specified by their id, all or those that are not governance.
- ID{ID}: Schema unique identifier.
- NOT_GOVERNANCE: All schemas except governance.
- ALL: All schemas.
Policies
This property defines the permissions of the users previously defined in the members section, granting them roles with respect to the schemas they have defined. Policies are defined independently for each scheme defined in governance.
- approve: Defines who the approvators are for the subjects that are created with that schema. Also, the quorum required to consider an event as approved.
- evaluate: Defines who the evaluators are for the subjects that are created with that schema. Also, the quorum required to consider an event as evaluated.
- validate: Defines who the validators are for the subjects that are created with that schema. Also, the quorum required to consider an event as validated.
What these data define is the type of quorum that must be reached for the event to pass this phase. There are 3 types of quorum:
- MAJORITY: This is the simplest one, it means that the majority, that is, more than 50% of the voters must sign the petition. It always rounds up, for example, in the case where there are 4 voters, the MAJORITY quorum would be reached when 3 give their signature.
- FIXED{fixed}: It’s pretty straightforward, it means that a fixed number of voters must sign the petition. For example, if a FIXED quorum of 3 is specified, this quorum will be reached when 3 voters have signed the petition.
- PERCENTAGE{percentage}: This is a quorum that is calculated based on a percentage of the voters. For example, if a PERCENTAGE quorum of 0.5 is specified, this quorum will be reached when 50% of the voters have signed the petition. It always rounds up.
In the event that a policy does not resolve for any member it will be returned to the governance owner. This allows, for example, that after the creation of the governance, when there are no declared members yet, the owner can evaluate, approve and validate the changes.
CAUTION
It is necessary to specify the permissions of all the schemes that are defined, there is no default assignment. Due to this, it is also necessary to specify the permissions of the governance scheme.3.1.2 - Governance scheme and contract
Scheme and contracts of governances
Governances in Kore are special subjects. Governances have a specific schema and contract defined within the Kore code. This is the case because prior configuration is necessary. This schema and contract must be the same for all participants in a network, otherwise failures can occur because a different result is expected, or the schema is valid for one participant but not for another. This schema and contract do not appear explicitly in the governance itself, but are within Kore and cannot be modified.
GOVERNANCE SCHEMA
Click to look at the full governance schema.
{
"$defs": {
"role": {
"type": "string",
"enum": ["VALIDATOR", "CREATOR", "ISSUER", "WITNESS", "APPROVER", "EVALUATOR"]
},
"quorum": {
"oneOf": [
{
"type": "string",
"enum": ["MAJORITY"]
},
{
"type": "object",
"properties": {
"FIXED": {
"type": "number",
"minimum": 1,
"multipleOf": 1
}
},
"required": ["FIXED"],
"additionalProperties": false
},
{
"type": "object",
"properties": {
"PERCENTAGE": {
"type": "number",
"minimum": 0,
"maximum": 1
}
},
"required": ["PERCENTAGE"],
"additionalProperties": false
}
]
}
},
"type": "object",
"additionalProperties": false,
"required": [
"members",
"schemas",
"policies",
"roles"
],
"properties": {
"members": {
"type": "array",
"items": {
"type": "object",
"properties": {
"name": {
"type": "string"
},
"id": {
"type": "string",
"format": "keyidentifier"
}
},
"required": [
"id",
"name"
],
"additionalProperties": false
}
},
"roles": {
"type": "array",
"items": {
"type": "object",
"properties": {
"who": {
"oneOf": [
{
"type": "object",
"properties": {
"ID": {
"type": "string"
}
},
"required": ["ID"],
"additionalProperties": false
},
{
"type": "object",
"properties": {
"NAME": {
"type": "string"
}
},
"required": ["NAME"],
"additionalProperties": false
},
{
"const": "MEMBERS"
},
{
"const": "ALL"
},
{
"const": "NOT_MEMBERS"
}
]
},
"namespace": {
"type": "string"
},
"role": {
"$ref": "#/$defs/role"
},
"schema": {
"oneOf": [
{
"type": "object",
"properties": {
"ID": {
"type": "string"
}
},
"required": ["ID"],
"additionalProperties": false
},
{
"const": "ALL"
},
{
"const": "NOT_GOVERNANCE"
}
]
}
},
"required": ["who", "role", "schema", "namespace"],
"additionalProperties": false
}
},
"schemas": {
"type": "array",
"minItems": 0,
"items": {
"type": "object",
"properties": {
"id": {
"type": "string"
},
"schema": {
"$schema": "http://json-schema.org/draft/2020-12/schema",
"$id": "http://json-schema.org/draft/2020-12/schema",
"$vocabulary": {
"http://json-schema.org/draft/2020-12/vocab/core": true,
"http://json-schema.org/draft/2020-12/vocab/applicator": true,
"http://json-schema.org/draft/2020-12/vocab/unevaluated": true,
"http://json-schema.org/draft/2020-12/vocab/validation": true,
"http://json-schema.org/draft/2020-12/vocab/meta-data": true,
"http://json-schema.org/draft/2020-12/vocab/format-annotation": true,
"http://json-schema.org/draft/2020-12/vocab/content": true
},
"$dynamicAnchor": "meta",
"title": "Core and validation specifications meta-schema",
"allOf": [
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://json-schema.org/draft/2020-12/meta/core",
"$vocabulary": {
"https://json-schema.org/draft/2020-12/vocab/core": true
},
"$dynamicAnchor": "meta",
"title": "Core vocabulary meta-schema",
"type": [
"object",
"boolean"
],
"properties": {
"$id": {
"$ref": "#/$defs/uriReferenceString",
"$comment": "Non-empty fragments not allowed.",
"pattern": "^[^#]*#?$"
},
"$schema": {
"$ref": "#/$defs/uriString"
},
"$ref": {
"$ref": "#/$defs/uriReferenceString"
},
"$anchor": {
"$ref": "#/$defs/anchorString"
},
"$dynamicRef": {
"$ref": "#/$defs/uriReferenceString"
},
"$dynamicAnchor": {
"$ref": "#/$defs/anchorString"
},
"$vocabulary": {
"type": "object",
"propertynames": {
"$ref": "#/$defs/uriString"
},
"additionalProperties": {
"type": "boolean"
}
},
"$comment": {
"type": "string"
},
"$defs": {
"type": "object",
"additionalProperties": {
"$dynamicRef": "#meta"
}
}
},
"$defs": {
"anchorString": {
"type": "string",
"pattern": "^[A-Za-z_][-A-Za-z0-9._]*$"
},
"uriString": {
"type": "string",
"format": "uri"
},
"uriReferenceString": {
"type": "string",
"format": "uri-reference"
}
}
},
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://json-schema.org/draft/2020-12/meta/applicator",
"$vocabulary": {
"https://json-schema.org/draft/2020-12/vocab/applicator": true
},
"$dynamicAnchor": "meta",
"title": "Applicator vocabulary meta-schema",
"type": [
"object",
"boolean"
],
"properties": {
"prefixItems": {
"$ref": "#/$defs/schemaArray"
},
"items": {
"$dynamicRef": "#meta"
},
"contains": {
"$dynamicRef": "#meta"
},
"additionalProperties": {
"$dynamicRef": "#meta"
},
"properties": {
"type": "object",
"additionalProperties": {
"$dynamicRef": "#meta"
},
"default": {}
},
"patternProperties": {
"type": "object",
"additionalProperties": {
"$dynamicRef": "#meta"
},
"propertynames": {
"format": "regex"
},
"default": {}
},
"dependentschemas": {
"type": "object",
"additionalProperties": {
"$dynamicRef": "#meta"
},
"default": {}
},
"propertynames": {
"$dynamicRef": "#meta"
},
"if": {
"$dynamicRef": "#meta"
},
"then": {
"$dynamicRef": "#meta"
},
"else": {
"$dynamicRef": "#meta"
},
"allOf": {
"$ref": "#/$defs/schemaArray"
},
"anyOf": {
"$ref": "#/$defs/schemaArray"
},
"oneOf": {
"$ref": "#/$defs/schemaArray"
},
"not": {
"$dynamicRef": "#meta"
}
},
"$defs": {
"schemaArray": {
"type": "array",
"minItems": 1,
"items": {
"$dynamicRef": "#meta"
}
}
}
},
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://json-schema.org/draft/2020-12/meta/unevaluated",
"$vocabulary": {
"https://json-schema.org/draft/2020-12/vocab/unevaluated": true
},
"$dynamicAnchor": "meta",
"title": "Unevaluated applicator vocabulary meta-schema",
"type": [
"object",
"boolean"
],
"properties": {
"unevaluatedItems": {
"$dynamicRef": "#meta"
},
"unevaluatedProperties": {
"$dynamicRef": "#meta"
}
}
},
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://json-schema.org/draft/2020-12/meta/validation",
"$vocabulary": {
"https://json-schema.org/draft/2020-12/vocab/validation": true
},
"$dynamicAnchor": "meta",
"title": "validation vocabulary meta-schema",
"type": [
"object",
"boolean"
],
"properties": {
"type": {
"anyOf": [
{
"$ref": "#/$defs/simpleTypes"
},
{
"type": "array",
"items": {
"$ref": "#/$defs/simpleTypes"
},
"minItems": 1,
"uniqueItems": true
}
]
},
"const": true,
"enum": {
"type": "array",
"items": true
},
"multipleOf": {
"type": "number",
"exclusiveMinimum": 0
},
"maximum": {
"type": "number"
},
"exclusiveMaximum": {
"type": "number"
},
"minimum": {
"type": "number"
},
"exclusiveMinimum": {
"type": "number"
},
"maxLength": {
"$ref": "#/$defs/nonNegativeInteger"
},
"minLength": {
"$ref": "#/$defs/nonNegativeIntegerDefault0"
},
"pattern": {
"type": "string",
"format": "regex"
},
"maxItems": {
"$ref": "#/$defs/nonNegativeInteger"
},
"minItems": {
"$ref": "#/$defs/nonNegativeIntegerDefault0"
},
"uniqueItems": {
"type": "boolean",
"default": false
},
"maxContains": {
"$ref": "#/$defs/nonNegativeInteger"
},
"minContains": {
"$ref": "#/$defs/nonNegativeInteger",
"default": 1
},
"maxProperties": {
"$ref": "#/$defs/nonNegativeInteger"
},
"minProperties": {
"$ref": "#/$defs/nonNegativeIntegerDefault0"
},
"required": {
"$ref": "#/$defs/stringArray"
},
"dependentRequired": {
"type": "object",
"additionalProperties": {
"$ref": "#/$defs/stringArray"
}
}
},
"$defs": {
"nonNegativeInteger": {
"type": "integer",
"minimum": 0
},
"nonNegativeIntegerDefault0": {
"$ref": "#/$defs/nonNegativeInteger",
"default": 0
},
"simpleTypes": {
"enum": [
"array",
"boolean",
"integer",
"null",
"number",
"object",
"string"
]
},
"stringArray": {
"type": "array",
"items": {
"type": "string"
},
"uniqueItems": true,
"default": []
}
}
},
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://json-schema.org/draft/2020-12/meta/meta-data",
"$vocabulary": {
"https://json-schema.org/draft/2020-12/vocab/meta-data": true
},
"$dynamicAnchor": "meta",
"title": "Meta-data vocabulary meta-schema",
"type": [
"object",
"boolean"
],
"properties": {
"title": {
"type": "string"
},
"description": {
"type": "string"
},
"default": true,
"deprecated": {
"type": "boolean",
"default": false
},
"readOnly": {
"type": "boolean",
"default": false
},
"writeOnly": {
"type": "boolean",
"default": false
},
"examples": {
"type": "array",
"items": true
}
}
},
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://json-schema.org/draft/2020-12/meta/format-annotation",
"$vocabulary": {
"https://json-schema.org/draft/2020-12/vocab/format-annotation": true
},
"$dynamicAnchor": "meta",
"title": "Format vocabulary meta-schema for annotation results",
"type": [
"object",
"boolean"
],
"properties": {
"format": {
"type": "string"
}
}
},
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://json-schema.org/draft/2020-12/meta/content",
"$vocabulary": {
"https://json-schema.org/draft/2020-12/vocab/content": true
},
"$dynamicAnchor": "meta",
"title": "content vocabulary meta-schema",
"type": [
"object",
"boolean"
],
"properties": {
"contentEncoding": {
"type": "string"
},
"contentMediaType": {
"type": "string"
},
"contentschema": {
"$dynamicRef": "#meta"
}
}
}
],
"type": [
"object",
"boolean"
],
"$comment": "This meta-schema also defines keywords that have appeared in previous drafts in order to prevent incompatible extensions as they remain in common use.",
"properties": {
"definitions": {
"$comment": "\"definitions\" has been replaced by \"$defs\".",
"type": "object",
"additionalProperties": {
"$dynamicRef": "#meta"
},
"deprecated": true,
"default": {}
},
"dependencies": {
"$comment": "\"dependencies\" has been split and replaced by \"dependentschemas\" and \"dependentRequired\" in order to serve their differing semantics.",
"type": "object",
"additionalProperties": {
"anyOf": [
{
"$dynamicRef": "#meta"
},
{
"$ref": "meta/validation#/$defs/stringArray"
}
]
},
"deprecated": true,
"default": {}
},
"$recursiveAnchor": {
"$comment": "\"$recursiveAnchor\" has been replaced by \"$dynamicAnchor\".",
"$ref": "meta/core#/$defs/anchorString",
"deprecated": true
},
"$recursiveRef": {
"$comment": "\"$recursiveRef\" has been replaced by \"$dynamicRef\".",
"$ref": "meta/core#/$defs/uriReferenceString",
"deprecated": true
}
}
},
"initial_value": {},
"contract": {
"type": "object",
"properties": {
"raw": {
"type": "string"
},
},
"additionalProperties": false,
"required": ["raw"]
},
},
"required": [
"id",
"schema",
"initial_value",
"contract"
],
"additionalProperties": false
}
},
"policies": {
"type": "array",
"items": {
"type": "object",
"additionalProperties": false,
"required": [
"id", "approve", "evaluate", "validate"
],
"properties": {
"id": {
"type": "string"
},
"approve": {
"type": "object",
"additionalProperties": false,
"required": ["quorum"],
"properties": {
"quorum": {
"$ref": "#/$defs/quorum"
}
}
},
"evaluate": {
"type": "object",
"additionalProperties": false,
"required": ["quorum"],
"properties": {
"quorum": {
"$ref": "#/$defs/quorum"
}
}
},
"validate": {
"type": "object",
"additionalProperties": false,
"required": ["quorum"],
"properties": {
"quorum": {
"$ref": "#/$defs/quorum"
}
}
}
}
}
}
}
}
And its initial state is:
{
"members": [],
"roles": [
{
"namespace": "",
"role": "WITNESS",
"schema": {
"ID": "governance"
},
"who": "MEMBERS"
}
],
"schemas": [],
"policies": [
{
"id": "governance",
"approve": {
"quorum": "MAJORITY"
},
"evaluate": {
"quorum": "MAJORITY"
},
"validate": {
"quorum": "MAJORITY"
}
}
]
}
Essentially, the initial state of the governance defines that all members added to the governance will be witnesses, and a majority of signatures from all members is required for any of the phases in the lifecycle of governance change events. However, it does not have any additional schemas, which will need to be added according to the needs of the use cases.
The governance contract is:
mod sdk;
use std::collections::HashSet;
use thiserror::Error;
use sdk::ValueWrapper;
use serde::{de::Visitor, ser::SerializeMap, Deserialize, Serialize};
#[derive(Clone)]
#[allow(non_snake_case)]
#[allow(non_camel_case_types)]
pub enum Who {
ID { ID: String },
NAME { NAME: String },
MEMBERS,
ALL,
NOT_MEMBERS,
}
impl Serialize for Who {
fn serialize<S>(&self, serializer: S) -> Result<S::Ok, S::Error>
where
S: serde::Serializer,
{
match self {
Who::ID { ID } => {
let mut map = serializer.serialize_map(Some(1))?;
map.serialize_entry("ID", ID)?;
map.end()
}
Who::NAME { NAME } => {
let mut map = serializer.serialize_map(Some(1))?;
map.serialize_entry("NAME", NAME)?;
map.end()
}
Who::MEMBERS => serializer.serialize_str("MEMBERS"),
Who::ALL => serializer.serialize_str("ALL"),
Who::NOT_MEMBERS => serializer.serialize_str("NOT_MEMBERS"),
}
}
}
impl<'de> Deserialize<'de> for Who {
fn deserialize<D>(deserializer: D) -> Result<Self, D::Error>
where
D: serde::Deserializer<'de>,
{
struct WhoVisitor;
impl<'de> Visitor<'de> for WhoVisitor {
type Value = Who;
fn expecting(&self, formatter: &mut std::fmt::Formatter) -> std::fmt::Result {
formatter.write_str("Who")
}
fn visit_map<A>(self, mut map: A) -> Result<Self::Value, A::Error>
where
A: serde::de::MapAccess<'de>,
{
// They should only have one entry
let Some(key) = map.next_key::<String>()? else {
return Err(serde::de::Error::missing_field("ID or NAME"))
};
let result = match key.as_str() {
"ID" => {
let id: String = map.next_value()?;
Who::ID { ID: id }
}
"NAME" => {
let name: String = map.next_value()?;
Who::NAME { NAME: name }
}
_ => return Err(serde::de::Error::unknown_field(&key, &["ID", "NAME"])),
};
let None = map.next_key::<String>()? else {
return Err(serde::de::Error::custom("Input data is not valid. The data contains unkown entries"));
};
Ok(result)
}
fn visit_string<E>(self, v: String) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
match v.as_str() {
"MEMBERS" => Ok(Who::MEMBERS),
"ALL" => Ok(Who::ALL),
"NOT_MEMBERS" => Ok(Who::NOT_MEMBERS),
other => Err(serde::de::Error::unknown_variant(
other,
&["MEMBERS", "ALL", "NOT_MEMBERS"],
)),
}
}
fn visit_borrowed_str<E>(self, v: &'de str) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
match v {
"MEMBERS" => Ok(Who::MEMBERS),
"ALL" => Ok(Who::ALL),
"NOT_MEMBERS" => Ok(Who::NOT_MEMBERS),
other => Err(serde::de::Error::unknown_variant(
other,
&["MEMBERS", "ALL", "NOT_MEMBERS"],
)),
}
}
}
deserializer.deserialize_any(WhoVisitor {})
}
}
#[derive(Clone)]
#[allow(non_snake_case)]
#[allow(non_camel_case_types)]
pub enum SchemaEnum {
ID { ID: String },
NOT_GOVERNANCE,
ALL,
}
impl Serialize for SchemaEnum {
fn serialize<S>(&self, serializer: S) -> Result<S::Ok, S::Error>
where
S: serde::Serializer,
{
match self {
SchemaEnum::ID { ID } => {
let mut map = serializer.serialize_map(Some(1))?;
map.serialize_entry("ID", ID)?;
map.end()
}
SchemaEnum::NOT_GOVERNANCE => serializer.serialize_str("NOT_GOVERNANCE"),
SchemaEnum::ALL => serializer.serialize_str("ALL"),
}
}
}
impl<'de> Deserialize<'de> for SchemaEnum {
fn deserialize<D>(deserializer: D) -> Result<Self, D::Error>
where
D: serde::Deserializer<'de>,
{
struct SchemaEnumVisitor;
impl<'de> Visitor<'de> for SchemaEnumVisitor {
type Value = SchemaEnum;
fn expecting(&self, formatter: &mut std::fmt::Formatter) -> std::fmt::Result {
formatter.write_str("Schema")
}
fn visit_map<A>(self, mut map: A) -> Result<Self::Value, A::Error>
where
A: serde::de::MapAccess<'de>,
{
// They should only have one entry
let Some(key) = map.next_key::<String>()? else {
return Err(serde::de::Error::missing_field("ID"))
};
let result = match key.as_str() {
"ID" => {
let id: String = map.next_value()?;
SchemaEnum::ID { ID: id }
}
_ => return Err(serde::de::Error::unknown_field(&key, &["ID", "NAME"])),
};
let None = map.next_key::<String>()? else {
return Err(serde::de::Error::custom("Input data is not valid. The data contains unkown entries"));
};
Ok(result)
}
fn visit_string<E>(self, v: String) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
match v.as_str() {
"ALL" => Ok(Self::Value::ALL),
"NOT_GOVERNANCE" => Ok(Self::Value::NOT_GOVERNANCE),
other => Err(serde::de::Error::unknown_variant(
other,
&["ALL", "NOT_GOVERNANCE"],
)),
}
}
fn visit_borrowed_str<E>(self, v: &'de str) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
match v {
"ALL" => Ok(Self::Value::ALL),
"NOT_GOVERNANCE" => Ok(Self::Value::NOT_GOVERNANCE),
other => Err(serde::de::Error::unknown_variant(
other,
&["ALL", "NOT_GOVERNANCE"],
)),
}
}
}
deserializer.deserialize_any(SchemaEnumVisitor {})
}
}
#[derive(Serialize, Deserialize, Clone)]
pub struct Role {
who: Who,
namespace: String,
role: RoleEnum,
schema: SchemaEnum,
}
#[derive(Serialize, Deserialize, Clone)]
pub enum RoleEnum {
VALIDATOR,
CREATOR,
ISSUER,
WITNESS,
APPROVER,
EVALUATOR,
}
#[derive(Serialize, Deserialize, Clone)]
pub struct Member {
id: String,
name: String,
}
#[derive(Serialize, Deserialize, Clone)]
pub struct Contract {
raw: String,
}
#[derive(Serialize, Deserialize, Clone)]
#[allow(non_snake_case)]
#[allow(non_camel_case_types)]
pub enum Quorum {
MAJORITY,
FIXED(u64),
PERCENTAGE(f64),
}
#[derive(Serialize, Deserialize, Clone)]
pub struct Validation {
quorum: Quorum,
}
#[derive(Serialize, Deserialize, Clone)]
pub struct Policy {
id: String,
approve: Validation,
evaluate: Validation,
validate: Validation,
}
#[derive(Serialize, Deserialize, Clone)]
pub struct Schema {
id: String,
schema: serde_json::Value,
initial_value: serde_json::Value,
contract: Contract,
}
#[repr(C)]
#[derive(Serialize, Deserialize, Clone)]
pub struct Governance {
members: Vec<Member>,
roles: Vec<Role>,
schemas: Vec<Schema>,
policies: Vec<Policy>,
}
// Define "Event family".
#[derive(Serialize, Deserialize, Debug)]
pub enum GovernanceEvent {
Patch { data: ValueWrapper },
}
#[no_mangle]
pub unsafe fn main_function(state_ptr: i32, event_ptr: i32, is_owner: i32) -> u32 {
sdk::execute_contract(state_ptr, event_ptr, is_owner, contract_logic)
}
// Contract logic with expected data types
// Returns the pointer to the data written with the modified state.
fn contract_logic(
context: &sdk::Context<Governance, GovernanceEvent>,
contract_result: &mut sdk::ContractResult<Governance>,
) {
// It would be possible to add error handling
// It could be interesting to do the operations directly as serde_json:Value instead of "Custom Data".
let state = &mut contract_result.final_state;
let _is_owner = &context.is_owner;
match &context.event {
GovernanceEvent::Patch { data } => {
// A JSON PATCH is received
// It is applied directly to the state
let patched_state = sdk::apply_patch(data.0.clone(), &context.initial_state).unwrap();
if let Ok(_) = check_governance_state(&patched_state) {
*state = patched_state;
contract_result.success = true;
contract_result.approval_required = true;
} else {
contract_result.success = false;
}
}
}
}
#[derive(Error, Debug)]
enum StateError {
#[error("A member's name is duplicated")]
DuplicatedMemberName,
#[error("A member's ID is duplicated")]
DuplicatedMemberID,
#[error("A policy identifier is duplicated")]
DuplicatedPolicyID,
#[error("No governace policy detected")]
NoGvernancePolicy,
#[error("It is not allowed to specify a different schema for the governnace")]
GovernanceShchemaIDDetected,
#[error("Schema ID is does not have a policy")]
NoCorrelationSchemaPolicy,
#[error("There are policies not correlated to any schema")]
PoliciesWithoutSchema,
}
fn check_governance_state(state: &Governance) -> Result<(), StateError> {
// We must check several aspects of the status.
// There cannot be duplicate members, either in name or ID.
check_members(&state.members)?;
// There can be no duplicate policies and the one associated with the governance itself must be present.
let policies_names = check_policies(&state.policies)?;
// Schema policies that do not exist cannot be indicated. Likewise, there cannot be
// schemas without policies. The correlation must be one-to-one
check_schemas(&state.schemas, policies_names)
}
fn check_members(members: &Vec<Member>) -> Result<(), StateError> {
let mut name_set = HashSet::new();
let mut id_set = HashSet::new();
for member in members {
if name_set.contains(&member.name) {
return Err(StateError::DuplicatedMemberName);
}
name_set.insert(&member.name);
if id_set.contains(&member.id) {
return Err(StateError::DuplicatedMemberID);
}
id_set.insert(&member.id);
}
Ok(())
}
fn check_policies(policies: &Vec<Policy>) -> Result<HashSet<String>, StateError> {
// Check that there are no duplicate policies and that the governance policy is included.
let mut is_governance_present = false;
let mut id_set = HashSet::new();
for policy in policies {
if id_set.contains(&policy.id) {
return Err(StateError::DuplicatedPolicyID);
}
id_set.insert(&policy.id);
if &policy.id == "governance" {
is_governance_present = true
}
}
if !is_governance_present {
return Err(StateError::NoGvernancePolicy);
}
id_set.remove(&String::from("governance"));
Ok(id_set.into_iter().cloned().collect())
}
fn check_schemas(
schemas: &Vec<Schema>,
mut policies_names: HashSet<String>,
) -> Result<(), StateError> {
// We check that there are no duplicate schemas.
// We also have to check that the initial states are valid according to the json_schema
// Also, there cannot be a schema with id "governance".
for schema in schemas {
if &schema.id == "governance" {
return Err(StateError::GovernanceShchemaIDDetected);
}
// There can be no duplicates and they must be matched with policies_names
if !policies_names.remove(&schema.id) {
// Not related to policies_names
return Err(StateError::NoCorrelationSchemaPolicy);
}
}
if !policies_names.is_empty() {
return Err(StateError::PoliciesWithoutSchema);
}
Ok(())
}
The governance contract is currently designed to only support one method/event - the “Patch”. This method allows us to send changes to the governance in the form of JSON-Patch, a standard format for expressing a sequence of operations to apply to a JavaScript Object Notation (JSON) document.
For instance, if we have a default governance and we want to make a change, such as adding a member, we would first calculate the JSON-Patch to express this change. This can be done using any tool that follows the JSON Patch standard RFC 6902, or with the use of our own tool, kore-patch.
This way, the governance contract leverages the flexibility of the JSON-Patch standard to allow for a wide variety of state changes while maintaining a simple and single method interface.
The contract has a close relationship with the schema, as it takes into account its definition to obtain the state before the execution of the contract and to validate it at the end of such execution.
Currently, it only has one function that can be called from an event of type Fact, the Patch method: Patch { data: ValueWrapper }. This method obtains a JSON patch that applies the changes it includes directly on the properties of the governance subject. At the end of its execution, it calls the function that checks that the final state obtained after applying the patch is a valid governance.
3.2 - Contracts
Contracts in Kore Ledger.
3.2.1 - Contracts in Kore
Introduction to contract programming in Kore Ledger.
Contracts & schemas
In Kore, each subject is associated to a schema that determines, fundamentally, its properties. The value of these properties may change over time through the emission of events, being necessary, consequently, to establish the mechanism through which these events perform such action. In practice, this is managed through a series of rules that constitute what we call a contract.
Consequently, we can say that a schema always has an associated contract that regulates how it evolves. The specification of both is done in governance.
Inputs and outputs
Contracts, although specified in the governance, are only executed by those nodes that have evaluation capabilities and have been defined as such in the governance rules. It is important to note that Kore allows a node to act as evaluator of a subject even if it does not possess the subject’s events chain, i.e., even if it is not witness. This helps to reduce the load on these nodes and contributes to the overall network performance.
To achieve the correct execution of a contract, it receives three inputs: the current state of the subject, the event to be processed and a flag indicating whether or not the event request has been issued by the owner of the subject. Once these inputs are received, the contract must use them to generate a new valid state. Note that the logic of the latter lies entirely with the contract programmer. The contract programmer also determines which events are valid, i.e. decides the family of events to be used. Thus, the contract will only accept events from this family, rejecting all others, and which the programmer can adapt, in terms of structure and data, to the needs of his use case. As an example, suppose a subject representing an user’s profile with his contact information as well as his identity; an event of the family could be one that only updates the user’s telephone number. On the other hand, the flag can be used to restrict certain operations to only the owner of the subject, since the execution of the contract is performed both by the events it generates on its own and by external invocations.
When a contract is finished executing, it generates three outputs:
-
Success flag: By means of a Boolean, it indicates whether the execution of the contract has been successful, in other words, whether the event should cause a change of state of the subject. This flag will be set to false whenever an error occurs in obtaining the input data of the contract or if the logic of the contract so dictates. In other words, it can and should be explicitly stated whether or not the execution can be considered successful. This is important because these decisions depend entirely on the use case, from which Kore is abstracted in its entirety. Thus, for example, the programmer could determine that if, after the execution of an event, the value of one of the subject properties has exceeded a threshold, the event cannot be considered valid.
-
Final state: If the event has been successfully processed and the execution of the contract has been marked as successful, then it returns the new state generated, which in practice could be the same as the previous one. This state will be validated against the schema defined in the governance to ensure the integrity of the information. If the validation is not successful, the success flag is cancelled.
-
Approval flag: The contract must decide whether or not an event should be approved. Again, this will depend entirely on the use case, being the responsibility of the programmer to establish when it is necessary. Thus, approval is set as an optional but also conditional phase.
CAUTION
Kore contracts work without any associated status. All the information they can work with is what they receive as input. This means that the value of variables is not retained between executions, marking an important difference with respect to contracts on other platforms, such as Ethereum.Life cycle
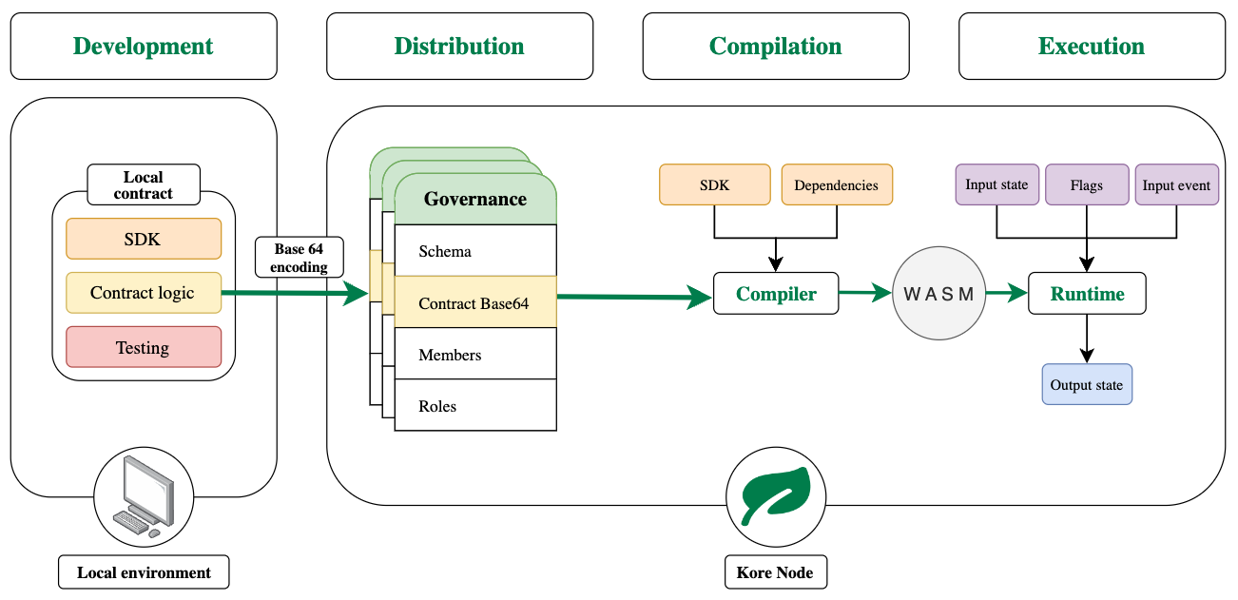
Development
Contracts are defined in local Rust projects, the only language allowed for writing them. These projects, which we must define as libraries, must import the SDK of the contracts available in the official repositories and, in addition, must follow the indications specified in “how to write a contract”.
Distribution
Once the contract has been defined, it must be included in a governance and associated to a schema so that it can be used by the nodes of a network. To this end, it is necessary to perform a governance update operation in which the contract is included in the corresponding section and coded in base64. If a test battery has been defined, it does not need to be included in the encoding process.
CAUTION
Since the Kore nodes are in charge of contract compilation, it is necessary that the base64 includes the contract in its entirety. In other words, the contract should be written entirely in a single file and encoded.
This is a current limitation and other alternatives are expected to be available in the future.
Compilation
If the update request is successful, the governance status will change and the evaluator nodes will compile the contract as a Web Assembly module, serialize it and store it in their database. This is an automated and self-managed process, so no user intervention is required at any stage of the process.
After this step, the contract can be used.
Execution
The execution of the contract will be done in a Web Assembly Runtime, isolating its execution from the rest of the system. This avoids the misuse of its resources, adding a layer of security.
Rust and WASM
Web Assembly is used for contract execution due to its characteristics:
- High performance and efficiency.
- It offers an isolated and secure execution environment.
- It has an active community.
- Allows compilation from several languages, many of them with a considerable user base.
- The modules resulting from the compilation, once optimized, are lightweight.
Rust was chosen as the language for writing Kore contracts because of its ability to compile to Web Assembly as well as its capabilities and specifications, the same reason that motivated its choice for the development of Kore. Specifically, Rust is a language focused on writing secure, high-performance code, both of which contribute to the quality of the resulting Web Assembly module. In addition, the language natively has the resources to create tests, which favors the testing of contracts.
3.2.2 - Programming contracts
How to program contracts.
SDK
For the correct development of the contracts it is necessary to use its SDK, a project that can be found in the official Kore repository. The main objective of this project is to abstract the programmer from the interaction with the context of the underlying evaluating machine, making it much easier to obtain the input data, as well as the process of writing the result of the contract.
The SDK project can be divided into three sections. On the one hand, a set of functions whose binding occurs at runtime and which are aimed at being able to interact with the evaluating machine, in particular, for reading and writing data to an internal buffer. Additionally, we also distinguish a module that, using the previous functions, is in charge of the serialization and deserialization of the data, as well as of providing the main function of any contract. Finally, we highlight a number of utility functions and structures that can be actively used in the code.
Many of the above elements are private, so the user will never have the opportunity to use them. Therefore, in this documentation we will focus on those that are exposed to the user and that the user will be able to actively use in the development of his contracts.
CAUTION
Please note that it is not possible to execute every function or use every type of data in a Web Assembly environment. You should inform yourself about the possibilities of the environment. For example, any interaction with the operating system is disabled, since it is an isolated and secure environment.Auxiliary structures
#[derive(Serialize, Deserialize, Debug)]
pub struct Context<State, Event> {
pub initial_state: State,
pub event: Event,
pub is_owner: bool,
}
This structure contains the three input data of any contract: the initial or current state of the subject, the incoming event and a flag indicating whether or not the person requesting the event is the owner of the subject. Note the use of generics for the state and the event.
#[derive(Serialize, Deserialize, Debug)]
pub struct ContractResult<State> {
pub final_state: State,
pub approval_required: bool,
pub success: bool,
}
It contains the result of the execution of the contract, being this a conjunction of the resulting state and two flags that indicate, on the one hand, if the execution has been successful according to the criteria established by the programmer (or if an error has occurred in the data loading); and on the other hand, if the event requires approval or not.
pub fn execute_contract<F, State, Event>(
state_ptr: i32,
event_ptr: i32,
is_owner: i32,
callback: F,
) -> u32
where
State: for<'a> Deserialize<'a> + Serialize + Clone,
Event: for<'a> Deserialize<'a> + Serialize,
F: Fn(&Context<State, Event>, &mut ContractResult<State>);
This function is the main function of the SDK and, likewise, the most important one. Specifically, it is in charge of obtaining the input data, data that it obtains from the context that it shares with the evaluating machine. The function, which will initially receive a pointer to each of these data, will be in charge of extracting them from the context and deserializing them to the state and event structures that the contract expects to receive, which can be specified by means of generics. These data, once obtained, are encapsulated in the Context structure present above and are passed as arguments to a callback function that manages the contract logic, i.e. it knows what to do with the data received. Finally, regardless of whether the execution has been successful or not, the function will take care of writing the result in the context, so that it can be used by the evaluating machine.
pub fn apply_patch<State: for<'a> Deserialize<'a> + Serialize>(
patch_arg: Value,
state: &State,
) -> Result<State, i32>;
This is the latest public feature of the SDK and allows to update a state by applying a JSON-PATCH, useful in cases where this technique is considered to update the state.
Your first contract
Creating the project
Locate the desired path and/or directories and create a new cargo package using cargo new NAME --lib. The project should be a library. Make sure you have a lib.rs file and not a main.rs file.
Then, include in the Cargo.toml as a dependency the SDK of the contracts and the rest of the dependencies you want from the following list:
- serde.
- serde_json.
- json_patch.
- thiserror.
The Cargo.toml should contain something like this:
[package]
name = "kore_contract"
version = "0.1.0"
edition = "2021"
[dependencies]
serde = { version = "=1.0.198", features = ["derive"] }
serde_json = "=1.0.116"
json-patch = "=1.2"
thiserror = "=1.0"
# Note: Change the tag label to the appropriate one
kore-contract-sdk = { git = "https://github.com/kore-ledger/kore-contract-sdk.git", branch = "main"}
Writing the contract
The following contract does not have a complicated logic since that aspect depends on the needs of the contract itself, but it does contain a wide range of the types that can be used and how they should be used. Since the compilation will be done by the node, we must write the whole contract in the lib.rs file.
In our case, we will start the contract by specifying the packages we are going to use.
use kore_contract_sdk as sdk;
use serde::{Deserialize, Serialize};
Next, it is necessary to specify the data structure that will represent the state of our subjects as well as the family of events that we will receive.
#[derive(Serialize, Deserialize, Clone)]
struct State {
pub text: String,
pub value: u32,
pub array: Vec<String>,
pub boolean: bool,
pub object: Object,
}
#[derive(Serialize, Deserialize, Clone)]
struct Object {
number: f32,
optional: Option<i32>,
}
#[derive(Serialize, Deserialize)]
enum StateEvent {
ChangeObject {
obj: Object,
},
ChangeOptional {
integer: i32,
},
ChangeAll {
text: String,
value: u32,
array: Vec<String>,
boolean: bool,
object: Object,
},
}
INFO
The event family will generally be defined as an enumerate, although in practice nothing prevents it from being a structure if required. Regardless of the case, if an enumerate is used, if its variants receive data, these must be specified by means of an anonymous structure and not by means of the tuple syntax.
It should also be noted that the events of the family can be subsets of the real events. Thus, as an example, the contract would accept a StateEvent::ChangeObject event that includes more data than the obj attribute. The contract, when executed, will only keep the necessary data, discarding all other data in the deserialization process. This could be used to store information in the string that is not needed for the contract logic.
CAUTION
Note that the implementation of the trait Serialize and Deserialize are mandatory to specify for state and events. Additionally, the former must also implement Clone.Next we define the contract entry function, the equivalent of the main function. It is important that this function always has the same name as the one specified here, since it is the identifier with which the evaluating machine will try to execute it, producing an error if it is not found.
#[no_mangle]
pub unsafe fn main_function(state_ptr: i32, event_ptr: i32, is_owner: i32) -> u32 {
sdk::execute_contract(state_ptr, event_ptr, is_owner, contract_logic)
}
This function must always be accompanied by the attribute #[no_mangle] and its input and output parameters must also match those of the example. Specifically, this function will receive the pointers to the input data, which will then be processed by the SDK function. As output, a new pointer to the result of the contract is generated, which, as mentioned above, is obtained by the SDK and not by the programmer.
INFO
Modifying the pointer values in this section of the code will have no effect. Pointers are with respect to the shared context, which corresponds to a single buffer per contract execution. Altering the pointer values does not allow the programmer to access arbitrary information either from the evaluating machine or from other contracts.Finally, we specify the logic of our contract, which can be defined by as many functions as we wish. Preferably a main function will be highlighted, which will be the one to be executed as callback by the execute_contract function of the SDK.
fn contract_logic(
context: &sdk::Context<State, StateEvent>,
contract_result: &mut sdk::ContractResult<State>,
) {
let state = &mut contract_result.final_state;
match &context.event {
StateEvent::ChangeObject { obj } => {
state.object = obj.to_owned();
}
StateEvent::ChangeOptional { integer } => state.object.optional = Some(*integer),
StateEvent::ChangeAll {
text,
value,
array,
boolean,
object,
} => {
state.text = text.to_string();
state.value = *value;
state.array = array.to_vec();
state.boolean = *boolean;
state.object = object.to_owned();
}
}
contract_result.success = true;
contract_result.approval_required = true;
}
This main function receives the contract input data encapsulated in an instance of the SDK Context structure. It also receives a mutable reference to the contract result containing the final state, originally identical to the initial state, and the approval required and successful execution flags, contract_result.approval_required and contract_result.success, respectively. Note how, in addition to modifying the status according to the event received, the previous flags must be modified. With the first flag we specify that the contract accepts the event and the changes it proposes for the current state of the subject, which will be translated in the SDK by generating a JSON_PATCH with the necessary modifications to move from the initial state to the obtained one. The second flag, on the other hand, allows us to conditionally indicate whether we consider that the event should be approved or not.
Testing your contract
Since this is Rust code, we can create a battery of unit tests in the contract code itself to check its performance using the resources of the language itself. It would also be possible to specify them in a different file.
// Testing Change Object
#[test]
fn contract_test_change_object() {
let initial_state = State {
array: Vec::new(),
boolean: false,
object: Object {
number: 0.5,
optional: None,
},
text: "".to_string(),
value: 24,
};
let context = sdk::Context {
initial_state: initial_state.clone(),
event: StateEvent::ChangeObject {
obj: Object {
number: 21.70,
optional: Some(64),
},
},
is_owner: false,
};
let mut result = sdk::ContractResult::new(initial_state);
contract_logic(&context, &mut result);
assert_eq!(result.final_state.object.number, 21.70);
assert_eq!(result.final_state.object.optional, Some(64));
assert!(result.success);
assert!(result.approval_required);
}
// Testing Change Optional
#[test]
fn contract_test_change_optional() {
let initial_state = State {
array: Vec::new(),
boolean: false,
object: Object {
number: 0.5,
optional: None,
},
text: "".to_string(),
value: 24,
};
// Testing Change Object
let context = sdk::Context {
initial_state: initial_state.clone(),
event: StateEvent::ChangeOptional { integer: 1000 },
is_owner: false,
};
let mut result = sdk::ContractResult::new(initial_state);
contract_logic(&context, &mut result);
assert_eq!(result.final_state.object.optional, Some(1000));
assert_eq!(result.final_state.object.number, 0.5);
assert!(result.success);
assert!(result.approval_required);
}
// Testing Change All
#[test]
fn contract_test_change_all() {
let initial_state = State {
array: Vec::new(),
boolean: false,
object: Object {
number: 0.5,
optional: None,
},
text: "".to_string(),
value: 24,
};
// Testing Change Object
let context = sdk::Context {
initial_state: initial_state.clone(),
event: StateEvent::ChangeAll {
text: "Kore_contract_test_all".to_string(),
value: 2024,
array: vec!["Kore".to_string(), "Ledger".to_string(), "SL".to_string()],
boolean: true,
object: Object {
number: 0.005,
optional: Some(2024),
},
},
is_owner: false,
};
let mut result = sdk::ContractResult::new(initial_state);
contract_logic(&context, &mut result);
assert_eq!(
result.final_state.text,
"Kore_contract_test_all".to_string()
);
assert_eq!(result.final_state.value, 2024);
assert_eq!(
result.final_state.array,
vec!["Kore".to_string(), "Ledger".to_string(), "SL".to_string()]
);
assert_eq!(result.final_state.boolean, true);
assert_eq!(result.final_state.object.optional, Some(2024));
assert_eq!(result.final_state.object.number, 0.005);
assert!(result.success);
assert!(result.approval_required);
}
As you can see, the only thing you need to do to create a valid test is to manually define an initial state and an incoming event instead of using the SDK executor function, which can only be properly executed by Kore. Once the inputs are defined, making a call to the main function of the contract logic should be sufficient.
Once the contract is tested, it is ready to be sent to Kore as indicated in the introduction section. Note that it is not necessary to send the contract tests to the Kore nodes. In fact, sending them will result in a higher byte usage of the encoded file and, consequently, as it is stored in the governance, a higher byte consumption of the governance.
3.3 - Learn JSON Schema
JSON Schema specification and examples.
JSON Schema specification
The JSON Schema specification is in DRAFT status in the IETF, however, it is widely used today and is practically considered a de facto standard.
JSON-Schema establishes a set of rules that model and validate a data structure. The following example defines a schema that models a simple data structure with 2 fields: id and value. It is also indicated that the id is mandatory and that no additional fields are allowed.
{
"type": "object",
"additionalProperties": false,
"required": [
"id"
],
"properties": {
"id": {"type":"string"},
"value": {"type":"integer"}
}
}
VALID JSON OBJECT
{
"id": "id_1",
"value": 23
}
INVALID JSON OBJECTS
{
"value": 3 // id is not defined and is mandatory
}
{
"id": "id_3",
"value": 3,
"count": 5 // additional properties are not allowed
}
JSON SCHEMA ONLINE VALIDATOR
You can test this behavior using this online and interactive JSON Schema validator.Creating a JSON-Schema
The following example is by no means definitive of all the value JSON Schema can provide. For this you will need to go deep into the specification itself. Learn more at json schema specification..
Let’s pretend we’re interacting with a JSON based car registration. This registration has a car which has:
- An manufacturer identifier:
chassisNumber - Identification of country of registration:
licensePlate - Number of kilometers driven:
mileage - An optional set of tags:
tags.
For example:
{
"chassisNumber": 72837362,
"licensePlate": "8256HYN",
"mileage": 60000,
"tags": [ "semi-new", "red" ]
}
While generally straightforward, the example leaves some open questions. Here are just a few of them:
- What is
chassisNumber? - Is
licensePlaterequired? - Can the
mileagebe less than zero? - Are all of the
tagsstring values?
When you’re talking about a data format, you want to have metadata about what keys mean, including the valid inputs for those keys. JSON Schema is a proposed IETF standard how to answer those questions for data.
Starting the schema
To start a schema definition, let’s begin with a basic JSON schema.
We start with four properties called keywords which are expressed as JSON keys.
Yes. the standard uses a JSON data document to describe data documents, most often that are also JSON data documents but could be in any number of other content types like
text/xml.
- The
$schemakeyword states that this schema is written according to a specific draft of the standard and used for a variety of reasons, primarily version control. - The
$idkeyword defines a URI for the schema, and the base URI that other URI references within the schema are resolved against. - The
titleanddescriptionannotation keywords are descriptive only. They do not add constraints to the data being validated. The intent of the schema is stated with these two keywords. - The
typevalidation keyword defines the first constraint on our JSON data and in this case it has to be a JSON Object.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://example.com/car.schema.json",
"title": "Car",
"description": "A registered car",
"type": "object"
}
We introduce the following pieces of terminology when we start the schema:
- Schema Keyword:
$schemaand$id. - Schema Annotations:
titleanddescription. - Validation Keyword:
type.
Defining the properties
chassisNumber is a numeric value that uniquely identifies a car. Since this is the canonical identifier for a var, it doesn’t make sense to have a car without one, so it is required.
In JSON Schema terms, we update our schema to add:
- The
propertiesvalidation keyword. - The
chassisNumberkey.descriptionschema annotation andtypevalidation keyword is noted – we covered both of these in the previous section.
- The
requiredvalidation keyword listingchassisNumber.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://example.com/car.schema.json",
"title": "Car",
"description": "A registered car",
"type": "object",
"properties": {
"chassisNumber": {
"description": "Manufacturer's serial number",
"type": "integer"
}
},
"required": [ "chassisNumber" ]
}
licensePlateis a string value that acting as a secondary identifier. Since there isn’t a car without a registration it also is required.- Since the
requiredvalidation keyword is an array of strings we can note multiple keys as required; We now includelicensePlate.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://example.com/car.schema.json",
"title": "Car",
"description": "A registered car",
"type": "object",
"properties": {
"chassisNumber": {
"description": "Manufacturer's serial number",
"type": "integer"
},
"licensePlate": {
"description": "Identification of country of registration",
"type": "string"
}
},
"required": [ "chassisNumber", "licensePlate" ]
}
Going deeper with properties
According to the car registry, they cannot have negative mileage.
- The
mileagekey is added with the usualdescriptionschema annotation andtypevalidation keywords covered previously. It is also included in the array of keys defined by therequiredvalidation keyword. - We specify that the value of
mileagemust be greater than or equal to zero using theminimumvalidation keyword.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://example.com/car.schema.json",
"title": "Car",
"description": "A registered car",
"type": "object",
"properties": {
"chassisNumber": {
"description": "Manufacturer's serial number",
"type": "integer"
},
"licensePlate": {
"description": "Identification of country of registration",
"type": "string"
},
"mileage": {
"description": "Number of kilometers driven",
"type": "number",
"minimum": 0
}
},
"required": [ "chassisNumber", "licensePlate", "mileage" ]
}
Next, we come to the tags key.
The car registry has established the following:
- If there are tags there must be at least one tag,
- All tags must be unique; no duplication within a single car.
- All tags must be text.
- Tags are nice but they aren’t required to be present.
Therefore:
- The
tagskey is added with the usual annotations and keywords. - This time the
typevalidation keyword isarray. - We introduce the
itemsvalidation keyword so we can define what appears in the array. In this case:stringvalues via thetypevalidation keyword. - The
minItemsvalidation keyword is used to make sure there is at least one item in the array. - The
uniqueItemsvalidation keyword notes all of the items in the array must be unique relative to one another. - We did not add this key to the
requiredvalidation keyword array because it is optional.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://example.com/car.schema.json",
"title": "Car",
"description": "A registered car",
"type": "object",
"properties": {
"chassisNumber": {
"description": "Manufacturer's serial number",
"type": "integer"
},
"licensePlate": {
"description": "Identification of country of registration",
"type": "string"
},
"mileage": {
"description": "Number of kilometers driven",
"type": "number",
"minimum": 0
},
"tags": {
"description": "Tags for the car",
"type": "array",
"items": {
"type": "string"
},
"minItems": 1,
"uniqueItems": true
}
},
"required": [ "chassisNumber", "licensePlate", "mileage" ]
}
Nesting data structures
Up until this point we’ve been dealing with a very flat schema – only one level. This section demonstrates nested data structures.
- The
dimensionskey is added using the concepts we’ve previously discovered. Since thetypevalidation keyword isobjectwe can use thepropertiesvalidation keyword to define a nested data structure.- We omitted the
descriptionannotation keyword for brevity in the example. While it’s usually preferable to annotate thoroughly in this case the structure and key names are fairly familiar to most developers.
- We omitted the
- You will note the scope of the
requiredvalidation keyword is applicable to the dimensions key and not beyond.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://example.com/car.schema.json",
"title": "Car",
"description": "A registered car",
"type": "object",
"properties": {
"chassisNumber": {
"description": "Manufacturer's serial number",
"type": "integer"
},
"licensePlate": {
"description": "Identification of country of registration",
"type": "string"
},
"mileage": {
"description": "Number of kilometers driven",
"type": "number",
"minimum": 0
},
"tags": {
"description": "Tags for the car",
"type": "array",
"items": {
"type": "string"
},
"minItems": 1,
"uniqueItems": true
},
"dimensions": {
"type": "object",
"properties": {
"length": {
"type": "number"
},
"width": {
"type": "number"
},
"height": {
"type": "number"
}
},
"required": [ "length", "width", "height" ]
}
},
"required": [ "chassisNumber", "licensePlate", "mileage" ]
}
Taking a look at data for our defined JSON Schema
We’ve certainly expanded on the concept of a car since our earliest sample data (scroll up to the top). Let’s take a look at data which matches the JSON Schema we have defined.
{
"chassisNumber": 1,
"licensePlate": "8256HYN",
"mileage": 60000,
"tags": [ "semi-new", "red" ],
"dimensions": {
"length": 4.005,
"width": 1.932,
"height": 1.425
}
}
INFO
This tutorial is based on “Getting Started Step-By-Step” JSON-Schema tutorial. If you want to learn more about JSON-Schema, visit the JSON-Schema website for the original tutorial and other resources.3.4 - Kore Base
Kore Base documentation.
3.4.1 - Architecture
Kore Base architecture.
Kore Base is a library that implements most of the functionality of the Kore protocols. The most straightforward way to develop a Kore-compliant application is to use this library as, for example, Kore Client does.
Internally, it is structured in a series of layers with different responsibilities. The following is a simplified layer and block level view of the Kore Base structure.
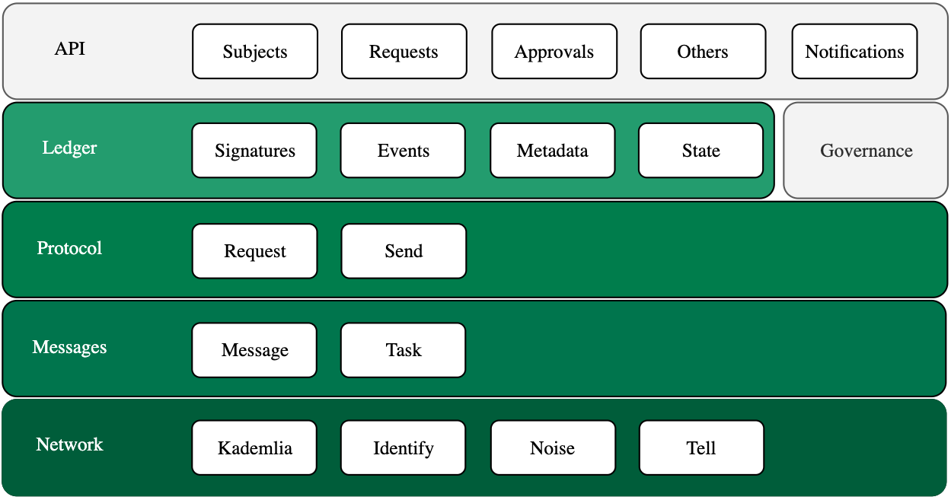
Network
Layer in charge of managing network communications, i.e., the sending and receiving of information between the different nodes of the network. Internally, the implementation is based on the use of LibP2P to resolve point-to-point communications. For this purpose, the following protocols are used:
- Kademlia, distributed hash table used as the foundation of peer routing functionality.
- Identify, protocol that allows peers to exchange information about each other, most notably their public keys and known network addresses.
- Noise, encryption scheme that allows for secure communication by combining cryptographic primitives into patterns with verifiable security properties.
- Tell, asynchronous protocol for sending messages. Tell arose within the development of Kore as an alternative to the LibP2P Request Response protocol that required waiting for responses.
Messages
Layer in charge of managing message sending tasks. The Kore communications protocol handles different types of messages. Some of them require a response. Since communications are asynchronous, we do not wait for an immediate response. This is why some types of messages have to be resent periodically until the necessary conditions are satisfied. This layer is responsible for encapsulating protocol messages and managing forwarding tasks.
Protocol
Layer in charge of managing the different types of messages of the Kore protocol and redirecting them to the parts of the application in charge of managing each type of message.
Ledger
Layer in charge of managing event chains, the micro-ledgers. This layer handles the management of subjects, events, status updates, updating of outdated chains, etc.
Governance
Module that manages the governances. Different parts of the application need to resolve conditions on the current or past state of some of the governance in which it participates. This module is in charge of managing these operations.
API
Layer in charge of exposing the functionality of the Kore node. Subject and event queries, request issuance or approval management are some of the functionalities exposed. A notification channel is also exposed in which different events occurring within the node are published, for example the creation of subjects or events.
3.4.2 - FFI
FFI implementation.
Kore has been designed with the intention that it can be built and run on different architectures, devices, and even from languages other than Rust.
Most of Kore’s functionality has been implemented in a library, Kore Base. However, this library alone does not allow running a Kore node since, for example, it needs a database implementation. This database must be provided by the software that integrates the Kore Base library. For example, Kore Client integrates a LevelDB database.
However, in order to run Kore on other architectures or languages we need a number of additional elements:
- Expose an Foreign Function Interface (FFI) that allows interacting with the Kore library from other languages.
- Target language bindings. Facilitating interaction with the library.
- Ability to cross-compile to the target architecture.
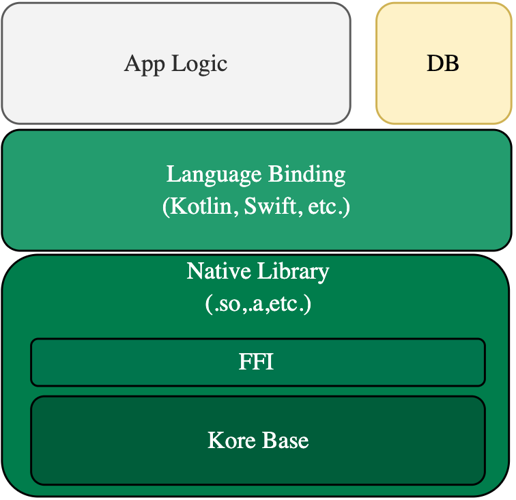
INFO
Explore the Kore repositories related to FFI for more information.3.5 - Kore Node
Intermediary between the different Kore Clients and Kore Base.
3.5.1 - What is
What is Kore Node?
Kore Node is an intermediary between Kore Base and the different Kore Clients such as Kore HTTP. Its main functions are 4:
- Create an API that will be consumed by the different Kore Clients in order to communicate with Kore Base, the objective of this API is the simplification of the types, that is, it is responsible for receiving basic types such as
Stringand converting them into complex types that Kore Base expects to receive as aDigestIdentifier. Another objective of this API is to combine different methods of the Kore Base API to perform a specific functionality such as creating a traceability subject, in this way we add an abstraction layer on top of the Kore Base API. - Implement the different methods that the databases need so that Kore Base can use them, in this way Kore Base is not coupled with any database and by defining some methods it is capable of working with a LevelDB, a SQlite or a Cassandra.
- Receive configuration parameters through
.toml,.yamland.jsonfiles; in addition toenvironment variables. To delve deeper into the configuration parameters, visit the following section. - Optionally expose a Prometheus to obtain metrics. For more information on prometheus configuration visit the next section.
Currently Kore Node consists of 3 features:
- sqlite: To make use of the
SQlitedatabase. - leveldb: To make use of the
LevelDBdatabase. - prometheus: to expose an API with an
endpointcalled/metricswhere metrics can be obtained.
INFO
To access more information about how Kore Node works, access the repository3.5.2 - Configuration
Configuration for Node Client Http
These configuration parameters are general to any node regardless of the type of client to be used, the specific parameters of each client will be found in their respective sections.
Configuring a node can be done in different ways. The supported mechanisms are listed below, from lowest to highest priority:
- Environment Variables.
- Configuration file.
Environment Variables
The following configuration parameters can only be configured through environment variables and as parameters to the binary that is generated when the client is compiled, but not using files:
| Environment variable | Description | Input parameter | What you receive |
KORE_PASSWORD |
Password that will be used to encrypt the cryptographic material | -p |
The password |
KORE_FILE_PATH |
Path of the configuration file to use | -f |
File path |
The parameters that can be configured through environment variables and files are:
| Environment variable | Description | What you receive | Default value |
KORE_PROMETHEUS |
Address and port where the server that contains the endpoint /metrics where the prometheus is located is going to be exposed |
An IP address and a port | 0.0.0.0:3050 |
KORE_KEYS_PATH |
Path where the private key will be saved in PKCS8 format encrypted with PKCS5 |
A directory | examples/keys |
KORE_DB_PATH |
Path where the database will be created if it does not exist or where the database is located if it already exists | A directory | For LevelDB examples/leveldb and for SQlite examples/sqlitedb |
KORE_NODE_KEY_DERIVATOR |
Key derivator to use |
A String with Ed25519 or Secp256k1 |
Ed25519 |
KORE_NODE_DIGEST_DERIVATOR |
Digest derivator to use |
>A String with Blake3_256, Blake3_512, SHA2_256, SHA2_512, SHA3_256 or SHA3_512 |
Blake3_256 |
KORE_NODE_REPLICATION_FACTOR |
Percentage of network nodes that receive protocol messages in an iteration | Float value | 0.25 |
KORE_NODE_TIMEOUT |
Waiting time to be used between protocol iterations | Unsigned integer value | 3000 |
KORE_NODE_PASSVOTATION |
Node behavior in the approval phase | Unsigned integer value, 1 to always approve, 2 to always deny, another value for manual approval | 0 |
KORE_NODE_SMARTCONTRACTS_DIRECTORY |
Directory where the subjects' contracts will be stored | A directory | Contracts |
KORE_NETWORK_PORT_REUSE |
True to configure port reuse for local sockets, which involves reusing listening ports for outgoing connections to improve NAT traversal capabilities. | Boolean Value | false |
KORE_NETWORK_USER_AGENT |
The user agent | The user agent | kore-node |
KORE_NETWORK_NODE_TYPE |
Node type | A String: Bootstrap, Addressable or Ephemeral | Bootstrap |
KORE_NETWORK_LISTEN_ADDRESSES |
Addresses where the node will listen | Addresses where the node will listen | /ip4/0.0.0.0/tcp/50000 |
KORE_NETWORK_EXTERNAL_ADDRESSES |
External address through which the node can be accessed, but it is not among its interfaces | External address through which the node can be accessed, but it is not among its interfaces | /ip4/90.0.0.70/tcp/50000 |
KORE_NETWORK_ROUTING_BOOT_NODES |
Addresses of the Boot Nodes in the P2P network to which we will connect to become part of the network | Addresses of the Boot Nodes, where if it has more than one address it will be separated with a _ and the addresses are separated from the Peer-ID of the node using /p2p/ |
|
KORE_NETWORK_ROUTING_DHT_RANDOM_WALK |
True to enable random walk in Kademlia DHT |
Boolean Value | true |
KORE_NETWORK_ROUTING_DISCOVERY_ONLY_IF_UNDER_NUM |
Number of active connections for which we interrupt the discovery process | Number of active connections | u64::MAX |
KORE_NETWORK_ROUTING_ALLOW_NON_GLOBALS_IN_DHT |
True if non-global addresses are allowed in the DHT | Boolean Value | false |
KORE_NETWORK_ROUTING_ALLOW_PRIVATE_IP |
If the address of a node is false, it cannot be private | Boolean Value | false |
KORE_NETWORK_ROUTING_ENABLE_MDNS |
True to activate mDNS | Boolean Value | true |
KORE_NETWORK_ROUTING_KADEMLIA_DISJOINT_QUERY_PATHS |
When enabled, the number of separate paths used is equal to the configured parallelism | Boolean Value | true |
KORE_NETWORK_ROUTING_KADEMLIA_REPLICATION_FACTOR |
The replication factor determines how many closest peers a record is replicated to | Unsigned integer value greater than 0 | false |
KORE_NETWORK_ROUTING_PROTOCOL_NAMES |
Protocols supported by the node | Protocols supported by the node | /kore/routing/1.0.0 |
KORE_NETWORK_TELL_MESSAGE_TIMEOUT_SECS |
Message waiting time | Number of seconds | 10 |
KORE_NETWORK_TELL_MAX_CONCURRENT_STREAMS |
Maximum number of simultaneous transmissions | Unsigned integer value | 100 |
KORE_NETWORK_CONTROL_LIST_ENABLE |
Enable access control list | Boolean value | true |
KORE_NETWORK_CONTROL_LIST_ALLOW_LIST |
List of allowed peers | Comma separated text string | Peer200,Peer300 |
KORE_NETWORK_CONTROL_LIST_BLOCK_LIST |
List of blocked peers | Comma separated text string | Peer1,Peer2 |
KORE_NETWORK_CONTROL_LIST_SERVICE_ALLOW_LIST |
List of allowed service URLs | Comma separated text string | http://90.0.0.1:3000/allow_list |
KORE_NETWORK_CONTROL_LIST_SERVICE_BLOCK_LIST |
List of blocked service URLs | Comma separated text string | http://90.0.0.1:3000/block_list |
KORE_NETWORK_CONTROL_LIST_INTERVAL_REQUEST |
Request interval in seconds | Number of seconds | 58 |
.json File
{
"kore": {
"network": {
"user_agent": "Kore2.0",
"node_type": "Addressable",
"listen_addresses": ["/ip4/127.0.0.1/tcp/50000","/ip4/127.0.0.1/tcp/50001","/ip4/127.0.0.1/tcp/50002"],
"external_addresses": ["/ip4/90.1.0.60/tcp/50000", "/ip4/90.1.0.61/tcp/50000"],
"tell": {
"message_timeout_secs": 58,
"max_concurrent_streams": 166
},
"control_list": {
"enable": true,
"allow_list": ["Peer200", "Peer300"],
"block_list": ["Peer1", "Peer2"],
"service_allow_list": ["http://90.0.0.1:3000/allow_list", "http://90.0.0.2:4000/allow_list"],
"service_block_list": ["http://90.0.0.1:3000/block_list", "http://90.0.0.2:4000/block_list"],
"interval_request": 99
},
"routing": {
"boot_nodes": ["/ip4/172.17.0.1/tcp/50000_/ip4/127.0.0.1/tcp/60001/p2p/12D3KooWLXexpg81PjdjnrhmHUxN7U5EtfXJgr9cahei1SJ9Ub3B","/ip4/11.11.0.11/tcp/10000_/ip4/12.22.33.44/tcp/55511/p2p/12D3KooWRS3QVwqBtNp7rUCG4SF3nBrinQqJYC1N5qc1Wdr4jrze"],
"dht_random_walk": false,
"discovery_only_if_under_num": 55,
"allow_non_globals_in_dht": true,
"allow_private_ip": true,
"enable_mdns": false,
"kademlia_disjoint_query_paths": false,
"kademlia_replication_factor": 30,
"protocol_names": ["/kore/routing/2.2.2","/kore/routing/1.1.1"]
},
"port_reuse": true
},
"node": {
"key_derivator": "Secp256k1",
"digest_derivator": "Blake3_512",
"replication_factor": 0.555,
"timeout": 30,
"passvotation": 50,
"smartcontracts_directory": "./fake_route"
},
"db_path": "./fake/db/path",
"keys_path": "./fake/keys/path",
"prometheus": "10.0.0.0:3030"
}
}
.toml File
[kore.network]
user_agent = "Kore2.0"
node_type = "Addressable"
port_reuse = true
listen_addresses = ["/ip4/127.0.0.1/tcp/50000","/ip4/127.0.0.1/tcp/50001","/ip4/127.0.0.1/tcp/50002"]
external_addresses = ["/ip4/90.1.0.60/tcp/50000","/ip4/90.1.0.61/tcp/50000"]
[kore.network.control_list]
enable = true
allow_list = ["Peer200", "Peer300"]
block_list = ["Peer1", "Peer2"]
service_allow_list = ["http://90.0.0.1:3000/allow_list", "http://90.0.0.2:4000/allow_list"]
service_block_list = ["http://90.0.0.1:3000/block_list", "http://90.0.0.2:4000/block_list"]
interval_request = 99
[kore.network.tell]
message_timeout_secs = 58
max_concurrent_streams = 166
[kore.network.routing]
boot_nodes = ["/ip4/172.17.0.1/tcp/50000_/ip4/127.0.0.1/tcp/60001/p2p/12D3KooWLXexpg81PjdjnrhmHUxN7U5EtfXJgr9cahei1SJ9Ub3B", "/ip4/11.11.0.11/tcp/10000_/ip4/12.22.33.44/tcp/55511/p2p/12D3KooWRS3QVwqBtNp7rUCG4SF3nBrinQqJYC1N5qc1Wdr4jrze"]
dht_random_walk = false
discovery_only_if_under_num = 55
allow_non_globals_in_dht = true
allow_private_ip = true
enable_mdns = false
kademlia_disjoint_query_paths = false
kademlia_replication_factor = 30
protocol_names = ["/kore/routing/2.2.2", "/kore/routing/1.1.1"]
[kore.node]
key_derivator = "Secp256k1"
digest_derivator = "Blake3_512"
replication_factor = 0.555
timeout = 30
passvotation = 50
smartcontracts_directory = "./fake_route"
[kore]
db_path = "./fake/db/path"
keys_path = "./fake/keys/path"
prometheus = "10.0.0.0:3030"
.yaml File
kore:
network:
control_list:
allow_list:
- "Peer200"
- "Peer300"
block_list:
- "Peer1"
- "Peer2"
service_allow_list:
- "http://90.0.0.1:3000/allow_list"
- "http://90.0.0.2:4000/allow_list"
service_block_list:
- "http://90.0.0.1:3000/block_list"
- "http://90.0.0.2:4000/block_list"
interval_request: 99
enable: true
user_agent: "Kore2.0"
node_type: "Addressable"
listen_addresses:
- "/ip4/127.0.0.1/tcp/50000"
- "/ip4/127.0.0.1/tcp/50001"
- "/ip4/127.0.0.1/tcp/50002"
external_addresses:
- "/ip4/90.1.0.60/tcp/50000"
- "/ip4/90.1.0.61/tcp/50000"
tell:
message_timeout_secs: 58
max_concurrent_streams: 166
routing:
boot_nodes:
- "/ip4/172.17.0.1/tcp/50000_/ip4/127.0.0.1/tcp/60001/p2p/12D3KooWLXexpg81PjdjnrhmHUxN7U5EtfXJgr9cahei1SJ9Ub3B"
- "/ip4/11.11.0.11/tcp/10000_/ip4/12.22.33.44/tcp/55511/p2p/12D3KooWRS3QVwqBtNp7rUCG4SF3nBrinQqJYC1N5qc1Wdr4jrze"
dht_random_walk: false
discovery_only_if_under_num: 55
allow_non_globals_in_dht: true
allow_private_ip: true
enable_mdns: false
kademlia_disjoint_query_paths: false
kademlia_replication_factor: 30
protocol_names:
- "/kore/routing/2.2.2"
- "/kore/routing/1.1.1"
port_reuse: true
node:
key_derivator: "Secp256k1"
digest_derivator: "Blake3_512"
replication_factor: 0.555
timeout: 30
passvotation: 50
smartcontracts_directory: "./fake_route"
db_path: "./fake/db/path"
keys_path: "./fake/keys/path"
prometheus: "10.0.0.0:3030"
3.6 - Kore Clients
Types of clients.
3.6.1 - Kore HTTP
Kore Base HTTP Client.
It is a kore base client that uses the HTTP protocol, it allows to interact through an api with the Kore Ledger nodes. If you want to access information about the Api.
It has a single configuration variable that is only obtained by environment variable.
| Environment variable | Description | What you receive | Default values |
KORE_HTTP_ADDRESS |
Address where we can access the api | IP address and port | 0.0.0.0:3000 |
INFO
To access more information about how Kore HTTP works, access the repositoryfurthermore, once the node is deployed in the/doc path, it can be interacted with through the rapidoc interface.
3.6.2 - Kore Modbus
Kore Base Modbus Client.
Coming soon
3.7 - Tools
Utilities to work with Kore Node
Kore Tools are a group of utilities developed to facilitate the use of Kore Node, especially during testing and prototyping. In this section we will go deeper into them and how they can be obtained and used.
Installation
There are different ways in which the user can acquire these tools. The first and most basic is the generation of their binaries through the compilation of their source code, which can be obtained through the public repositories. However, we recommend making use of the available docker images in conjunction with a series of scripts that abstract the use of these images, so that the user does not need to compile the code.
Compiling binaries
$ git clone git@github.com:kore-ledger/kore-tools.git
$ cd kore-tools
$ sudo apt install -y libprotobuf-dev protobuf-compiler cmake
$ cargo install --locked --path keygen
$ cargo install --locked --path patch
$ cargo install --locked --path sign
$ kore-keygen -h
$ kore-sign -h
$ kore-patch -h
TIP
These utilities may be used relatively frequently, so we recommend that you include the scripts in the PATH to simplify their use.Kore Keygen
Any Kore node needs cryptographic material to function. To do so, it is necessary to generate it externally and then indicate it to the node, either by means of environment variables or through input parameters. The Kore Keygen utility satisfies this need by allowing, in a simple way, the generation of this cryptographic material. Specifically, its execution allows to obtain a private key in hexadecimal format, as well as the identifier (controller ID) which is the identifier at Kore level in which its format includes the public key, plus information of the cryptographic scheme used (you can obtain more information in the following link).
# Generate pkcs8 encrpty with pkcs5(ED25519)
kore-keygen -p a
kore-keygen -p a -r keys-Ed25519/private_key.der
kore-keygen -p a -r keys-Ed25519/public_key.der -d public-key
# Generate pkcs8 encrpty with pkcs5(SECP256K1)
kore-keygen -p a -m secp256k1
kore-keygen -p a -r keys-secp2561k/private_key.der -m secp256k1
kore-keygen -p a -r keys-secp2561k/public_key.der -m secp256k1 -d public-key
INFO
X and the other tools accept different execution arguments. For more information, try –help, for example:
Kore-keygen --help
Kore Sign
This is an utility that is intended to facilitate the execution of external invocations. In order to provide context, an external invocation is the process by which a node proposes a change to a network subject that it does not control, i.e., of which it is not the owner. There are also a number of rules that regulate which network users have the ability to perform these operations. In either case, the invoking node must present, in addition to the changes it wishes to suggest, a valid signature to prove its identity.
Kore Sign allows precisely the latter, generating the necessary signature to accompany the request for changes. Additionally, as the utility is strictly intended for such a scenario, what is actually returned by its execution is the entire data structure (in JSON format) that must be delivered to other nodes in the network for them to consider the request.
For the correct operation of the utility, it is necessary to pass as arguments both the event request data and the private key in hexadecimal format to be used.
# Basic usage example
kore-sign --id-private-key 2a71a0aff12c2de9e21d76e0538741aa9ac6da9ff7f467cf8b7211bd008a3198 '{"Transfer":{"subject_id":"JjyqcA-44TjpwBjMTu9kLV21kYfdIAu638juh6ye1gyU","public_key":"E9M2WgjXLFxJ-zrlZjUcwtmyXqgT1xXlwYsKZv47Duew"}}'
// Output in json format
{
"request": {
"Transfer": {
"subject_id": "JjyqcA-44TjpwBjMTu9kLV21kYfdIAu638juh6ye1gyU",
"public_key": "E9M2WgjXLFxJ-zrlZjUcwtmyXqgT1xXlwYsKZv47Duew"
}
},
"signature": {
"signer": "EtbFWPL6eVOkvMMiAYV8qio291zd3viCMepUL6sY7RjA",
"timestamp": 1717684953822643000,
"content_hash": "J1XWoQaLArB5q6B_PCfl4nzT36qqgoHzG-Uh32L_Q3cY",
"value": "SEYml_XhryHvxRylu023oyR0nIjlwVCyw2ZC_Tgvf04W8DnEzP9I3fFpHIc0eHrp46Exk8WIlG6fT1qp1bg1WgAg"
}
}
CAUTION
It is important to note that currently only private keys of the ED25519 algorithm are supportedTIP
If you need to pass the evento request to Kore-sign through a pipe instead of as an argument, you can use the xargs utility. For example,
echo '{"Transfer":{"subject_id":"JjyqcA-44TjpwBjMTu9kLV21kYfdIAu638juh6ye1gyU","public_key":"E9M2WgjXLFxJ-zrlZjUcwtmyXqgT1xXlwYsKZv47Duew"}}' | xargs -0 -I {} kore-sign --id-private-key 2a71a0aff12c2de9e21d76e0538741aa9ac6da9ff7f467cf8b7211bd008a3198 {}
Kore Patch
Currently the contract that handles governance changes only allows one type of event that includes a JSON Patch.
JSON Patch is a data format that represents changes to JSON data structures. Thus, starting from an initial structure, after applying the JSON Patch, an updated structure is obtained. In the case of Kore, the JSON Patch defines the changes to be made to the data structure that represents governance when it needs to be modified. Kore Patch allows us to calculate the JSON Patch in a simple way if we have the original governance and the modified governance.
# Basic usage example
kore-patch '{"members":[]}' '{"members":[{"id":"EtbFWPL6eVOkvMMiAYV8qio291zd3viCMepUL6sY7RjA","name":"ACME"}]}'
// Output in json format
[
{
"op": "add",
"path": "/members/0",
"value": {
"id": "EtbFWPL6eVOkvMMiAYV8qio291zd3viCMepUL6sY7RjA",
"name": "ACME"
}
}
]
Once the JSON Patch is obtained it can be included in an event request to be sent to the governance owner.
TIP
Although Kore Patch has been developed to facilitate modifications to Kore governance, it is really just a utility that generates a JSON PATH from 2 JSON objects, so it can be used for other purposes.Control
Tool to provide a list of allowed and blocked nodes. It has 3 environment variables SERVERS that allows you to indicate how many servers you want and on which port you want them to listen and two lists ALLOWLIST and BLOCKLIST. These lists will be the default ones but you have a /allow and /block route with PUT and GET to modify them.
export SERVERS="0.0.0.0:3040,0.0.0.0:3041"
export ALLOWLIST="172.10.10.2"
control
Output
Server started at: 0.0.0.0:3040
Server started at: 0.0.0.0:3041
4 - Policies
Kore Ledger policy documents.
4.1 - Legal warning
Legal warning statement of Kore Ledger.
1. Legal information
This website is the property of Kore Ledger, S.L., with an address at Calle Tomas Baulen Y Ponte 72 38500. 38500, Guimar (Santa Cruz De Tenerife) Spain and tax identification number B56696545.
2. Conditions of use
By accessing and using this website, you agree to comply with the following terms and conditions, if you don’t mind. If you disagree with these terms, please don’t use the site.
3. Intellectual property
All contents of this website, including, but not limited to, text, graphics, logos, images, and software, are the property of Kore Ledge and are protected by Spanish intellectual property laws. It is prohibited from reproduction, distribution, or modification without the express consent of the owner of this website.
4. Privacy
Personal information collected through this site is used by our Privacy Policy, which you can consult at this link.
5.Limitation of liability
Kore Ledger is not responsible for any direct or indirect damages from using this website, including data loss, service interruptions, or other technical problems.
6. Links
Links to other websites may be mentioned from this website. Kore Ledger is not responsible for the availability, content, and possible damages or losses suffered by visiting these websites since they are governed by their terms and conditions, over which Kore Ledger has no control.
7. Applicable law and jurisdiction
This legal notice is governed by Spanish law, and any dispute related to this legal notice will be subject to the jurisdiction of the courts of Santa Cruz de Tenerife.
8. Modifications
We reserve the right to change this legal notice at any time. Changes will be effective as soon as they are posted on the site.
9. Contact
If you have any questions or comments about this legal notice, please contact us at support@kore-ledger.net.
4.2 - Privacy
Kore Ledger privacy statement.
1. Information about the person responsible for the treatment
- Responsible for the treatment: Kore Ledger, S.L.
- Registered office: Calle Tomas Baulen Y Ponte 72 38500, Güímar (Santa Cruz De Tenerife)
- Tax identification number: B56696545
- Contact email: support@kore-ledger.net
2. Processing of personal data
We collect and process this website’s users’ personal data by Spanish legislation and the GDPR. Personal data is managed transparently and used only for the specific purposes for which it was provided.
3. Purposes of data processing
Personal data is collected for the following purposes:
- Sending information about products, promotions, or relevant updates.
- Customer service and support.
4. Legal basis for processing
The legal basis for processing personal data is the user’s consent and the legitimate interests pursued by Kore Ledger, S.L.
5. User consent
You agree to its processing for this privacy policy by providing your data.
6. User rights
Users have the right to access, rectify, cancel, and oppose the processing of their data. To exercise these rights, you can contact us at support@kore-ledger.net. You can find forms to exercise your rights at: https://www.aepd.es/derechos-y-deberes/conoce-tus-derechos If you consider that your data is being treated inappropriately, you can file a claim with the supervisory authority (Spanish Data Protection Agency). For more information on this point you can consult: https://www.aepd.es/preguntas-frecuentes/13-reclamaciones-ante-aepd-y-ante-otros-organismos-competentes/FAQ-1301-como-puedo-interponer-una-reclamacion-si-han-vulnerado-mis-datos-de-caracter-personal
7. Share data with third parties
We do not share personal data with third parties except when necessary to comply with legal obligations or provide services related to the website’s operation.
8. Data security
We adopt appropriate security measures to protect personal data against loss, misuse, or unauthorized access.
9. Cookies
This website uses cookies to improve user experience. You can obtain more information in our Cookies Policy [link to cookie policy].
10. Changes to the privacy policy
We reserve the right to make changes to this privacy policy. Any modification will be notified on this page.
11. Contact
For any questions or comments about this privacy policy, please get in touch with us through our contact email: support@kore-ledger.net.
4.3 - Equality and diversity
Kore ledger commitment to equality and diversity.
Kore Ledger’s Commitment to Equality and diversity
Kore Ledger, S.L. declares its commitment to the establishment and development of policies that integrate equal treatment and opportunities between women and men, without direct or indirect discrimination based on sex, as well as the imposition and promotion of measures to achieve real equality within our organisation, establishing equal opportunities between women and men as a strategic principle of our Corporate and Human Resources Policy, in accordance with the definition of this principle established by the Organic Law 3/2007, of 22 March, for effective equality between women and men.
In each and every one of the areas in which this company operates, from recruitment to promotion, including wage policy, training, working and employment conditions, occupational health, organisation of working time and work-life balance, we accept the principle of equal opportunities between women and men, paying special attention to indirect discrimination, which is understood as ‘the situation in which an apparently neutral provision, criterion or practice places a person of one sex at a particular disadvantage compared to a person of the other sex’.
With regard to communication, both internally and externally, all decisions taken in this respect will be reported and an image of the company will be projected in accordance with this principle of equal opportunities between women and men.
The principles set out above will be put into practice through the promotion of equality measures or through the implementation of an Equality Plan that will lead to improvements with respect to the current situation, with the corresponding monitoring systems being set up, with the aim of making progress in achieving real equality between women and men in the company and, by extension, in society as a whole.
To this end, the legal representation of male and female workers will be involved, not only in the collective bargaining process, as established in Organic Law 3/2007 for effective equality between women and men, but also in the whole process of development and evaluation of the aforementioned equality measures or Equality Plan.